




- @maoku66
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
HuggingFace推出的Skills功能让AI模型微调变得像点菜一样简单。通过自然语言指令,开发者无需专业机器学习知识即可完成模型训练、量化和部署。该功能将复杂流程抽象为三层:自然语言理解层、标准流程层和硬件操作层,支持SFT、DPO、GRPO等多种训练方式。用户只需5分钟安装插件,就能通过对话完成从数据准备到模型部署的全流程。虽然降低了技术门槛,但仍需注意数据质量、成本控制和领域适配等问题。
具身智能的强化学习之路,是一场从理论算法到物理直觉的深刻融合。PPO是可靠的起点,其稳定性让你能专注于理解RL训练的基本循环和具身智能的独特挑战。SAC是高效的进阶,其最大熵框架和自动调参特性,使其成为解决复杂任务的首选。模仿学习是强大的助推器,能用专家知识显著加速训练进程。领域随机化和课程学习是跨越“仿真-现实”鸿沟的桥梁,它们让算法学会的不是一个特解,而是应对变化的通法。展望未来,具身智能的研
PPO像一位配备全职教练团的严师,体系完备,监督严密,但培养成本极高。GRPO像一位组织小组竞赛的引导者,通过内部竞争激发潜能,效率高且能催生“思维链”等高级能力,特别适合有明确规则的任务。DPO像一位品味鉴赏家,通过直接对比“好”与“坏”来塑造模型的判断力,简单、稳定、高效,是调整模型风格与安全性的利器。技术演进的趋势越来越清晰:从复杂走向简洁,从依赖外部奖励走向激发内部竞争或直接对齐人类偏好。
区正在探索更优方案,例如DPO等直接偏好优化算法,试图绕过复杂的强化学习过程。但无论如何,PPO作为大模型对齐技术的开拓者和现阶段事实上的标准,其思想将持续影响未来。
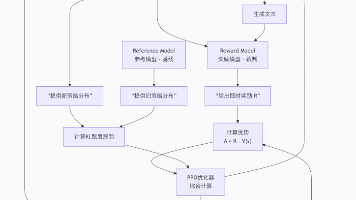
具身智能的强化学习之路,是一场从理论算法到物理直觉的深刻融合。PPO是可靠的起点,其稳定性让你能专注于理解RL训练的基本循环和具身智能的独特挑战。SAC是高效的进阶,其最大熵框架和自动调参特性,使其成为解决复杂任务的首选。模仿学习是强大的助推器,能用专家知识显著加速训练进程。领域随机化和课程学习是跨越“仿真-现实”鸿沟的桥梁,它们让算法学会的不是一个特解,而是应对变化的通法。展望未来,具身智能的研
HuggingFace推出的Skills功能让AI模型微调变得像点菜一样简单。通过自然语言指令,开发者无需专业机器学习知识即可完成模型训练、量化和部署。该功能将复杂流程抽象为三层:自然语言理解层、标准流程层和硬件操作层,支持SFT、DPO、GRPO等多种训练方式。用户只需5分钟安装插件,就能通过对话完成从数据准备到模型部署的全流程。虽然降低了技术门槛,但仍需注意数据质量、成本控制和领域适配等问题。
向量化计算是发动机技术,让大规模数学运算得以高效执行。向量与嵌入是翻译官,将人类语义翻译成机器能懂的数学语言。向量数据库是超级索引器,专门负责在海量“数学坐标”中瞬间找到“最近邻居”。这三者环环相扣,共同构成了当前AI应用,特别是RAG和推荐系统的技术基石。展望未来,向量数据库的发展趋势已清晰可见:多模融合:从单一的文本向量,到同时处理文本、图像、音频、视频嵌入的“多模态向量数据库”,实现“用文字
PPO像一位配备全职教练团的严师,体系完备,监督严密,但培养成本极高。GRPO像一位组织小组竞赛的引导者,通过内部竞争激发潜能,效率高且能催生“思维链”等高级能力,特别适合有明确规则的任务。DPO像一位品味鉴赏家,通过直接对比“好”与“坏”来塑造模型的判断力,简单、稳定、高效,是调整模型风格与安全性的利器。技术演进的趋势越来越清晰:从复杂走向简洁,从依赖外部奖励走向激发内部竞争或直接对齐人类偏好。
通过这份详尽的对比,我们可以清晰地看到,企业级RAG的落地之战,本质上是**“分散集成模式”与“一体化平台模式”** 之间的较量。AWS DIY路径提供了极致的灵活性和组件选择自由,但代价是极高的集成复杂性、持续攀升的运营成本和对庞大精英团队的依赖。它适合拥有强大云架构和运维团队的超大型科技公司。EDB Postgres AI等一体化平台路径通过产品化的集成、预建的AI流水线和本地化部署,在成本、
云环境准备 -> 工具安装 -> 数据与配置准备 -> 启动训练 -> 效果验证。这个模式可以迁移到几乎任何其他开源模型和自定义数据集上。总结一下核心收获:微调的本质:是让通用大模型在特定知识或任务上“专业化”的高效手段。QLoRA等高效微调技术:极大降低了个人开发者和研究者的尝试门槛。开源工具(LLaMA Factory)和云平台(ModelScope):是帮助我们快速上手、聚焦创意而非环境的利