




- @m0_72372080
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
部署了很多次Grounding Sam,每次都在这一步卡了几十分钟之后才想起来要怎么解决。在保证路径全对的情况下,安装这个包即可。
部署了很多次Grounding Sam,每次都在这一步卡了几十分钟之后才想起来要怎么解决。在保证路径全对的情况下,安装这个包即可。
【代码】解决:cannot import name ‘AutoModel‘ from ‘modelscope‘
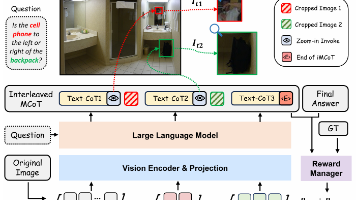
而 O3 是在看图的过程中就对图进行思考,在思考过程中,会有 Tool_Call 的过程。之前的一篇自动驾驶的结合了 Tool Call 的论文,调用的工具不仅仅只有图像放大,还有目标检测等等。上图是论文的一个示例,展示他们是如何把 Tool Call 加入到思维链中,从而形成对图的动态思考的。那么此时的状态就定义为所有的文本的裁剪的图片。论文对于这个任务中的状态(强化学习的那个状态)设置为:文本
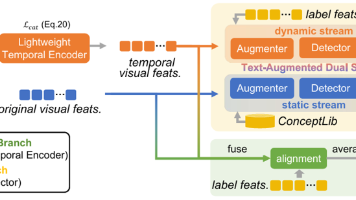
这篇论文是第二篇开放词汇视频异常检测(OVVAD)的论文。其实第一篇OVVAD的论文做的方法很简单,但是之所以能投CVPR,是因为提出了OVVAD这个任务。这篇论文没有“第一个提出”这块招牌,也就是说它得在方法上下功夫,才能中CVPR。(就是说检测不到新类)和(就是说无法把新类异常归类),这两个挑战其实也就是OVVAD的两个核心挑战。而论文的创新是引入了“文本增强的双流机制”,我会在后面解释这个机
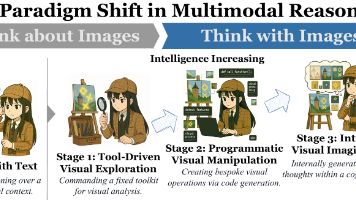
一篇将视觉强化微调的各种方法总结起来的综述被提出来了,这篇综述将对图像的思考分成了两种:Think About Image 和 Think With Image。前者仅仅是把图像静态输入给大模型,作为一次上下文;后者是动态输入图片,类似看 - 想 - 看的迭代式思考。近两年来,强化微调已经火得不像话了,相关论文每个月就有好几篇挂在 Arxiv 上,看都看不过来。
多半是环境的问题,最主要的是 python 版本要高。
【代码】解决:cannot import name ‘AutoModel‘ from ‘modelscope‘