




- @m0_71592416
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在当今海量的用户生成内容(UGC)处理中,文本数据(评论、弹幕、标题)与音频数据(语音识别结果、背景音乐特征)正成为AI模型训练与推理的重要输入源。这些数据经过特征提取(如NLP的Token Embedding、音频的MFCC/梅尔频谱特征)后,普遍呈现出一个关键特征:高维稀疏性。
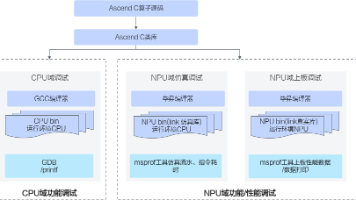
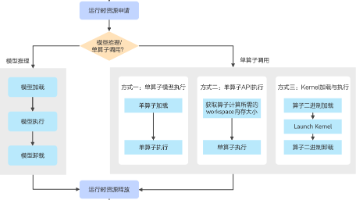
华为 CANN 在 2025 版本中引入更完备的算子孪生调试(Twin Debug)机制,将编译器、执行框架、仿真工具与线下调试流程打通,使开发者在本地即可精准复现问题、分析瓶颈、进行算子级性能优化。本文将从工程视角深入剖析孪生调试的原理、价值与典型调试方式,构建开发者可直接使用的算子调试全流程知识体系。

动态Shape算子是提升AI模型适配性和灵活性的关键技术手段。CANN提供了丰富的接口和机制,从Shape推导、算子选择器、Kernel注册到内存管理,都为开发者提供了充分的控制能力。在开发过程中,合理设计Tiling策略、严格执行异常处理和内存管理,是保证算子高效稳定运行的核心。

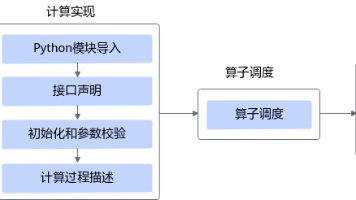
本文面向工程实践者,系统讲解如何用华为昇腾(CANN)提供的 TBE DSL(Domain-Specific Language)快速实现自定义算子。文章从 DSL 的设计理念与工作流切入,逐步覆盖算子分析、计算实现、自动调度(Auto Schedule)原理、编译与验证、以及在精度/性能维度的优化技巧与常见陷阱。文中穿插端到端的 Add 算子示例,并给出工程化注意点与排错思路,帮助你把算子从“数学
在昇腾 CANN 体系中,环境是否正确往往决定你后续的整个开发流程是否顺利。无论你是准备在 AI Core 上编写自定义算子、要将模型转换为 OM 文件,还是准备调试端到端的训练/推理程序,环境搭建都是第一道必须跨过的门槛。

在昇腾 AI 处理器生态中,算子是模型执行性能的最小基本单元。如何让算子既具备可控性,又能充分释放硬件的潜能,是算子开发者必须解决的核心问题。TIK(Tensor Iterator Kernel)正是在这样的背景下应运而生——它以 Python 的灵活性为入口,通过 DSL 编译体系连接到底层的 CCE 编译器,将高层描述转化为适配昇腾 AI Core 的高效二进制代码。
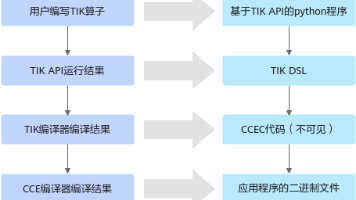
在昇腾 AI 处理器生态中,TIK(Tensor Iterator Kernel)是算子开发者最常用也最核心的底层编程模型之一。它构建在 TBE(Tensor Boost Engine)之上,通过一套接近硬件执行模型的 Python DSL,开发者可以直接操控 Unified Buffer、L1 Buffer、AI Core 指令等底层资源,从而实现任意数据布局、任意算子逻辑的高性能计算。
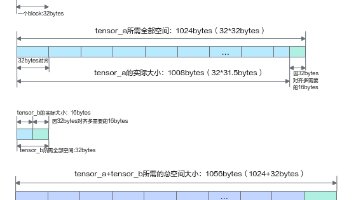
在越来越多的 AI 应用落地过程中,开发者会发现一个共同趋势:实际工程往往不仅包含模型推理,还涉及大量独立的数学运算、数据转换、图像处理等前后处理逻辑。如果这些部分也能直接利用昇腾 AI 处理器的算力,那么整体系统的性能才能真正被完全释放。
在昇腾 AI 处理器上进行 TIK(Tensor Iterator Kernel)算子开发时,数据搬运是最基础、也是最容易影响性能的环节。算子能否高效运行,很大程度上取决于开发者是否理解 GM(Global Memory)与 UB(Unified Buffer)之间的数据流模式、对齐要求、搬运粒度以及跨循环的计算布局。
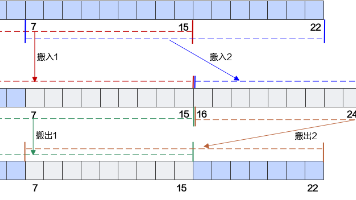
矩阵乘法(Matmul)是深度学习计算图中最核心、最昂贵的算子之一。无论是 Transformer 的注意力,CNN 的全连接层,还是大模型中的每一次前向与后向传播,本质上都由大量的 GEMM(General Matrix Multiplication)堆叠而成。在 CPU 上,你可能只需要调用 BLAS;在 GPU 上,你可以依赖 cuBLAS;但在昇腾平台上,如果你想真正理解性能的来源,或者为
