




- @m0_68969027
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
HCC高性能集群针对大模型场景,集成了腾讯太极机器学习平台AngelPTM等自研框架,其加速引擎对网络协议、通信策略、AI框架、模型编译进行大量系统级优化,大幅节约训练成本。相比上一代,服务器带宽从1.6T提升到3.2T,算力性能提升3倍。

腾讯推出的高性能网络星脉,具备业界最高的3.2T通信带宽,为AI大模型带来10倍通信性能提升。基于腾讯云新一代算力集群HCC,可支持10万卡GPU的超大计算规模。

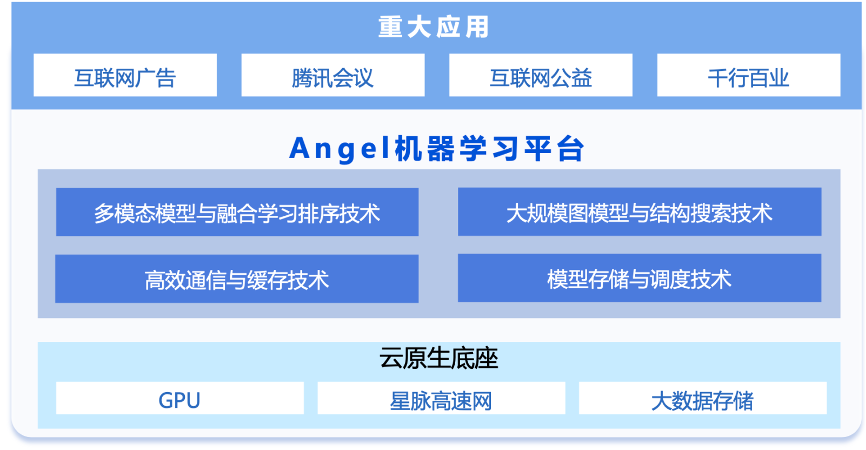
为了提高训练效率,TB级机器学习模型通常采用分布式训练方法,需要大量的参数和梯度同步,以1.8T模型千卡训练为例,IO通信量达到25TB, 耗时占比53%,此外,加上不同算力集群间的异构网络环境,通信网络延迟不一,这些都对模型训练过程中的通信开销提出了较高的要求。另外,针对面向推荐系统的图模型训练, 腾讯Angel机器学习平台设计了图节点特征自适应图网络结构搜索技术,可自动输出最优结构,解决了TB
本文主要介绍了在TVMCon 2023 上发布的 BlazerML 加速强化学习推理的方案,并分享 CPU 上高性能卷积算子的优化等技术细节,相关功能已经基于“开悟”落地腾讯太极机器学习平台。

腾讯推出的高性能网络星脉,具备业界最高的3.2T通信带宽,为AI大模型带来10倍通信性能提升。基于腾讯云新一代算力集群HCC,可支持10万卡GPU的超大计算规模。
混元AI大模型先后在MSR-VTT,MSVD等五大权威数据集榜单中登顶,实现跨模态领域的大满贯,并再次登顶自然语言理解任务榜单CLUE。如此来势汹汹的“混元”,落地到具体的应用场景是如何发挥其效能的呢? 我们一起来看看它背后的技术揭秘。

鉴于最近大模型的火热趋势,腾讯云决定将腾讯太极机器学习平台自研的AngelPTM训练框架推广给广大公有云用户,该框架经腾讯内部业务的反复打磨,低成本高性能支撑万亿大模型的训练落地,帮助业务降本增效。

HCC高性能集群针对大模型场景,集成了腾讯太极机器学习平台AngelPTM等自研框架,其加速引擎对网络协议、通信策略、AI框架、模型编译进行大量系统级优化,大幅节约训练成本。相比上一代,服务器带宽从1.6T提升到3.2T,算力性能提升3倍。
混元AI大模型先后在MSR-VTT,MSVD等五大权威数据集榜单中登顶,实现跨模态领域的大满贯,并再次登顶自然语言理解任务榜单CLUE。如此来势汹汹的“混元”,落地到具体的应用场景是如何发挥其效能的呢? 我们一起来看看它背后的技术揭秘。
鉴于最近大模型的火热趋势,腾讯云决定将腾讯太极机器学习平台自研的AngelPTM训练框架推广给广大公有云用户,该框架经腾讯内部业务的反复打磨,低成本高性能支撑万亿大模型的训练落地,帮助业务降本增效。