- @m0_68949064
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据收集:数据清洗:数据标注:数据分割:预训练模型:自定义模型:硬件选择:软件环境:分布式训练:超参数调优:训练过程:正则化技术:模型保存与加载:模型评估:模型优化:部署环境:API接口:持续集成与部署(CI/CD):监控与维护:数据隐私:模型偏见:可解释性:python代码这个示例展示了如何使用PyTorch训练一个简单的图像分类模型。请根据具体需求和数据情况调整模型和训练过程。

DeepSeek凭借其强大的技术实力、低廉的价格和开源策略,正在重新定义AI模型的使用方式。其核心产品DeepSeek-V3和DeepSeek-R1在多个领域展示了卓越的性能,为开发者和企业提供了一个经济高效且功能强大的AI工具。如果你对DeepSeek感兴趣,可以访问其官方网站(DeepSeek)或GitHub仓库(https://github.com/deepseek-ai)获取更多信息和资源
数据收集:数据清洗:数据标注:数据分割:预训练模型:自定义模型:硬件选择:软件环境:分布式训练:超参数调优:训练过程:正则化技术:模型保存与加载:模型评估:模型优化:部署环境:API接口:持续集成与部署(CI/CD):监控与维护:数据隐私:模型偏见:可解释性:python代码这个示例展示了如何使用PyTorch训练一个简单的图像分类模型。请根据具体需求和数据情况调整模型和训练过程。
数据收集:数据清洗:数据标注:数据分割:预训练模型:自定义模型:硬件选择:软件环境:分布式训练:超参数调优:训练过程:正则化技术:模型保存与加载:模型评估:模型优化:部署环境:API接口:持续集成与部署(CI/CD):监控与维护:数据隐私:模型偏见:可解释性:python代码这个示例展示了如何使用PyTorch训练一个简单的图像分类模型。请根据具体需求和数据情况调整模型和训练过程。
数据大模型的发展正处于一个关键的转折点,既面临着诸多挑战,也孕育着无限机遇。未来,随着技术的不断进步和应用场景的不断拓展,大模型将在更多领域发挥重要作用,为人类社会的发展带来更多的创新和进步。

根据业务需求和存储需求,可以在紧密耦合的体系结构中针对主存储部署数据存储,并且可以将数据分为节点之间的很小的块,或者在独立的松散耦合结构中不存储数据跨节点,并提供更大的灵活性。在这个基础上,以其中一个节点作为响应前端请求的节点(active node),另一个节点作为工程的备份节点(standby node),避免单机不可用导致系统停止造成的损失(业务中断、数据/模板丢失),并且在 active

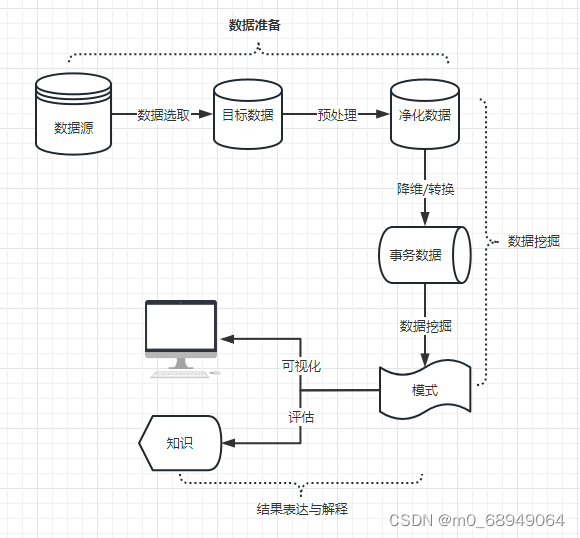
数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
DeepSeek凭借其强大的技术实力、低廉的价格和开源策略,正在重新定义AI模型的使用方式。其核心产品DeepSeek-V3和DeepSeek-R1在多个领域展示了卓越的性能,为开发者和企业提供了一个经济高效且功能强大的AI工具。如果你对DeepSeek感兴趣,可以访问其官方网站(DeepSeek)或GitHub仓库(https://github.com/deepseek-ai)获取更多信息和资源
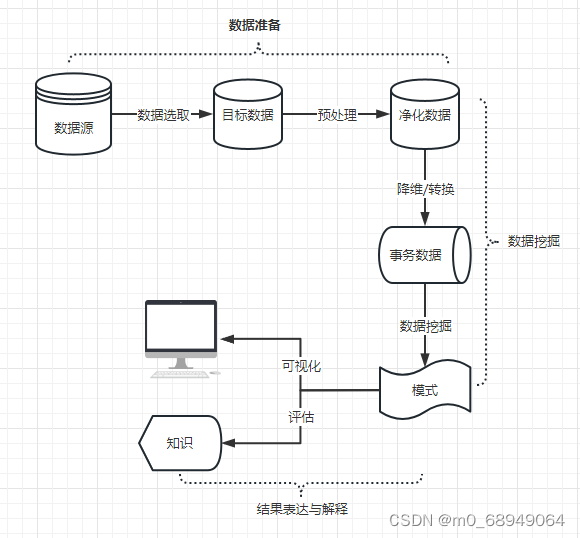
数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。