




- @m0_65010824
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文是对论文《BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation》的深度解读。在自动驾驶感知领域,多传感器融合面临几何失真与语义损失的双重挑战。MIT 团队提出的 BEVFusion 框架,创新性地将多模态特征统一到共享鸟瞰图空间,通过优化 BEV 池化实现 40 倍效率提升,兼

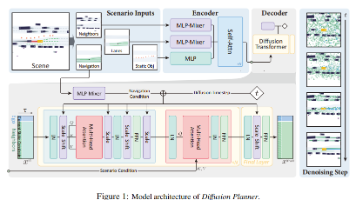
本文是对论文《Diffusion-Based Planning for Autonomous Driving with Flexible Guidance》的深度解读。在自动驾驶规划领域,复杂环境下类人驾驶行为实现与多目标平衡是核心挑战。研究团队创新性提出 Diffusion Planner,基于扩散模型与 Transformer 架构,联合建模预测与规划任务,通过灵活分类器引导机制,无需规则化优
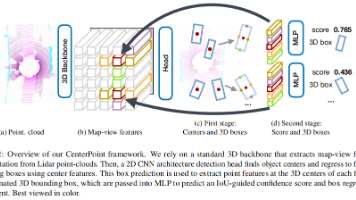
摘要:本文是对论文《Center-based 3D Object Detection and Tracking》的深度解读。在自动驾驶 3D 感知领域,传统锚框方法难以适配旋转目标与稀疏点云的挑战。UT Austin 团队提出的 CenterPoint 框架,创新性地将 3D 目标表示为中心点,通过两阶段检测与速度预测实现高效跟踪,在 Waymo 和 nuScenes 数据集上达成 SOTA 性能
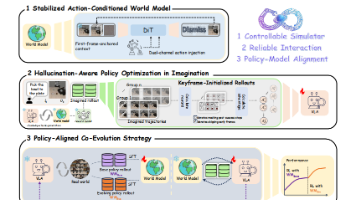
本文是对论文《WoVR: World Models as Reliable Simulators ...》的深度解读。在机器人操作领域,VLA 模型的 RL 后训练受限于真实世界交互成本与世界模型幻觉问题,成为核心研究挑战。多机构联合团队提出的 WoVR 框架,从可控模拟器设计、可靠交互协议、策略 - 模型对齐三层显式控制幻觉,实现了稳定的长视野想象滚动,在 LIBERO 基准和真实机器人任务中大
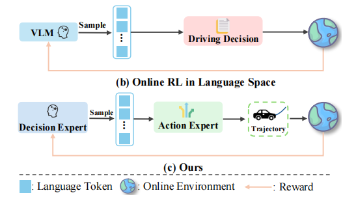
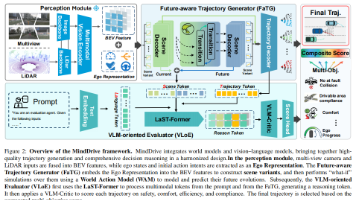
本文是对论文《MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning》的深度解读。在自动驾驶领域,VLA模型依赖模仿学习存在分布偏移与因果混淆问题,在线强化学习应用受限于连续动作空间探索低效。该研究创新提出MindDrive框架,通过双LoRA专家架构实现语
本文是对论文《Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)》的深度解读。在E2E自驾领域,RL应用受原始传感器数据复杂性、训练难度高的困扰,模仿学习则存在因果混淆等局限。上交等团队提出的Raw2Drive,创新设计双流模型基强化学
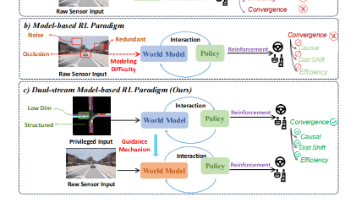
本文是对论文《WoVR: World Models as Reliable Simulators ...》的深度解读。在机器人操作领域,VLA 模型的 RL 后训练受限于真实世界交互成本与世界模型幻觉问题,成为核心研究挑战。多机构联合团队提出的 WoVR 框架,从可控模拟器设计、可靠交互协议、策略 - 模型对齐三层显式控制幻觉,实现了稳定的长视野想象滚动,在 LIBERO 基准和真实机器人任务中大
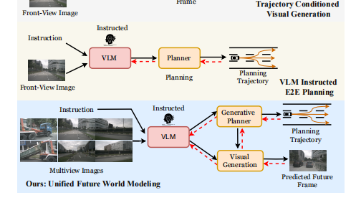
本文是对论文《UniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving》的深度解读。在自动驾驶领域,现有方法常将感知、规划与生成割裂,存在信息瓶颈。研究团队提出统一世界模型 UniDrive-WM,在单一 VLM 架构中集成场景理解、轨迹规划与未来图像生成,通过离散
本文是对论文《MindDrive: An All-in-One Framework Bridging World Models and Vision-Language Model for End-to-End Autonomous Driving》的深度解读。在端到端自动驾驶领域,轨迹规划中生成与选择失衡是关键挑战。北航等团队提出的 MindDrive 框架,创新整合世界模型与视觉语言模型,通过未
本文是对论文《LoRA: Low-Rank Adaptation of Large Language Models》的深度解读。在大语言模型快速发展的背景下,全参数微调面临存储成本高、显存占用大、部署低效等难题。微软团队提出的 LoRA 低秩适配方法,通过冻结预训练模型权重、注入可训练低秩矩阵,在不引入推理延迟的情况下大幅减少了适配参数量与训练开销。
