




- @m0_62929945
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
关联分析是关联规则挖掘,目标是发现事务数据库中不同项之间的联系,这些联系构成的规则可以帮助用户找出某些行为的特征。

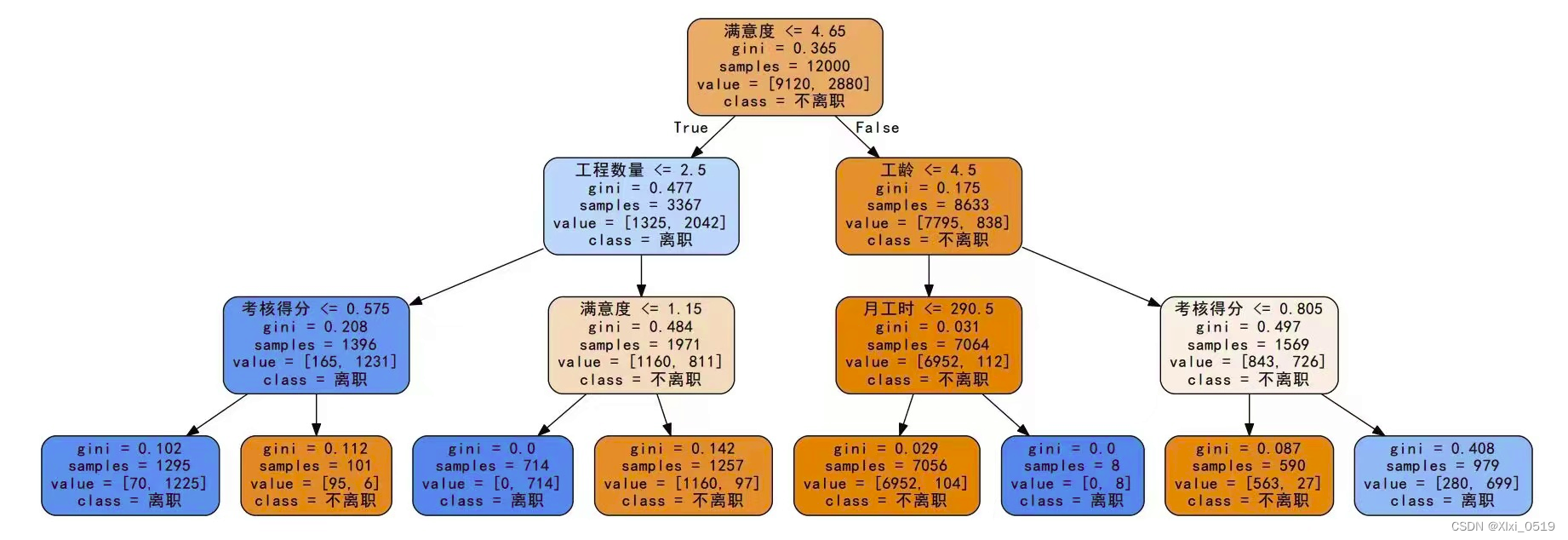
建立IF-THEN分类规则,即每个内部属性值形成规则前件(IF部分)的一个合取项,叶子结点形成规则后件(THEN部分)注意这里对数函数以2为底是因为信息用二进制位编码,但并非不可改变。无条件熵反映了该属性中各类别取值的平均自信息量,即平均不确定值。决策树由:根节点、内部节点和叶子节点。前两者的作用在于根据属性对对对象进行划分,而后者是分类的结果。熵是指类别属性的不确定性,而决策树算法的本质是通过描
关联分析是关联规则挖掘,目标是发现事务数据库中不同项之间的联系,这些联系构成的规则可以帮助用户找出某些行为的特征。
首先是导入和绘图定制操作上述代码设置了x和y随机数,接下来调用plt.plot()函数绘图。如果只提供y值,plot以索引值为x值。接下来介绍2D图表的几项基本设置。一般而言,对于包含多个单独的子集,且每个子集的绘制有不同的标准时,可以通过直接绘图(这种情况下plot函数会自动分类数据)或者申明具体数据组来绘图,同时添加其他通用函数以及进一步的注释帮助用户理解。特别地,如果出现两组数据的刻度差别过

在布莱克-斯科尔斯-默顿定价公式中,价格的波动率是无法直接观测到的。在金融市场上波动率被投资者用于衡量资产价格波动的剧烈程度,而资产价格波动本质上反映了资产蕴含的风险,例如股票的波动率用于度量股票收益产生的不确定性,通常介于15%-60%之间。波动率一般分为历史波动率、已实现波动率、预期波动率和隐含波动率。在实际中,交易员通常使用隐含波动率(implied volatility),这一波动率是指由
建立IF-THEN分类规则,即每个内部属性值形成规则前件(IF部分)的一个合取项,叶子结点形成规则后件(THEN部分)注意这里对数函数以2为底是因为信息用二进制位编码,但并非不可改变。无条件熵反映了该属性中各类别取值的平均自信息量,即平均不确定值。决策树由:根节点、内部节点和叶子节点。前两者的作用在于根据属性对对对象进行划分,而后者是分类的结果。熵是指类别属性的不确定性,而决策树算法的本质是通过描
用少数几个不可观测的随机变量(因子)去描述许多随机变量之间的协方差关系。主义因子分析可以视作主成分分析的一种推广,但因子是不可观察且不必是相互正交的变量。其基本思想是:根据相关性大小将变量分组,每组变量代表一个基本结构,反映观测到的相关性。R型因子分析可以用来研究变量之间的相关关系,Q型因子分析研究样品之间的相关关系,二者知识形式上的不同数学处理上是一样的,本文以R型因子为例展开说明。
正常的数据类型分为三种:横截面数据、时间序列数据和面板数据三类。其中,时间序列是按照一定的时间间隔排列的一组数据,其时间间隔可以是任意的时间单位,如小时、日、周月等。在本例中为每天某产品的需求量,这些数据形成了以一定时间间隔的数据。时间序列数据包含时间要素和数值要素,通过对这些时间序列的分析,从中发现和揭示现象发展变化的规律,并将这些知识和信息用于预测。比如需求量是上升还是下降,是否与季节有关,是

关联分析是关联规则挖掘,目标是发现事务数据库中不同项之间的联系,这些联系构成的规则可以帮助用户找出某些行为的特征。
建立IF-THEN分类规则,即每个内部属性值形成规则前件(IF部分)的一个合取项,叶子结点形成规则后件(THEN部分)注意这里对数函数以2为底是因为信息用二进制位编码,但并非不可改变。无条件熵反映了该属性中各类别取值的平均自信息量,即平均不确定值。决策树由:根节点、内部节点和叶子节点。前两者的作用在于根据属性对对对象进行划分,而后者是分类的结果。熵是指类别属性的不确定性,而决策树算法的本质是通过描