




- @m0_62232347
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
模型性能分析:模型的准确率为0.91,表明模型在大多数情况下能够正确预测用户的购买意向。这是一个积极的指标,显示模型具有较高的可靠性。精确率为0.84,意味着模型预测的购买用户中有84%是正确的。这有助于提高营销活动的目标性和效率。召回率为0.54,相对较低,指出模型未能识别出近一半的实际购买用户。这可能导致错失销售机会,需要通过调整模型策略或阈值来提升。AUC为0.93,显示模型在区分不同类别方

本次数据集来自UCI机器学习库中的电信流失数据集。该数据集是在 12 个月内从伊朗某电信公司数据库中随机收集的。通过收集客户数据、清洗、选择关键特征、建立预测模型、评估和优化模型等步骤,帮助企业了解客户行为模式,并采取相应措施来最大程度地减少流失、提高留存。

模型性能分析:模型的准确率为0.91,表明模型在大多数情况下能够正确预测用户的购买意向。这是一个积极的指标,显示模型具有较高的可靠性。精确率为0.84,意味着模型预测的购买用户中有84%是正确的。这有助于提高营销活动的目标性和效率。召回率为0.54,相对较低,指出模型未能识别出近一半的实际购买用户。这可能导致错失销售机会,需要通过调整模型策略或阈值来提升。AUC为0.93,显示模型在区分不同类别方
除了以上几种优化还可以从其他方面进行改进:1.本案例中,填充缺失值的方法选择常见类别填充,除此之外还可以选择使用一些机器学习算法预测缺失值进行填充;2.特征编码方法的选择也会影响模型的构建,可以尝试其他编码方法后,选择最佳一种;3.本数据集的正样本和负样本明显不均衡,下一个优化方向可以是对此进行改进;4.调整RFECV方法的基模型或者是选择其他特征选择方法,得到新的特征子集,新的特征子集有可能带来

中的。用于分类或回归问题,通常用作分类算法。在处理一个未知样本时,先找出训练集中距离K个已知样本,然后根据这K个已知样本的类别标签来预测测试集样本的类别。在分类问题中,通常选择出现作为预测结果;在回归问题中,则计算这K个临近值的作为预测结果。
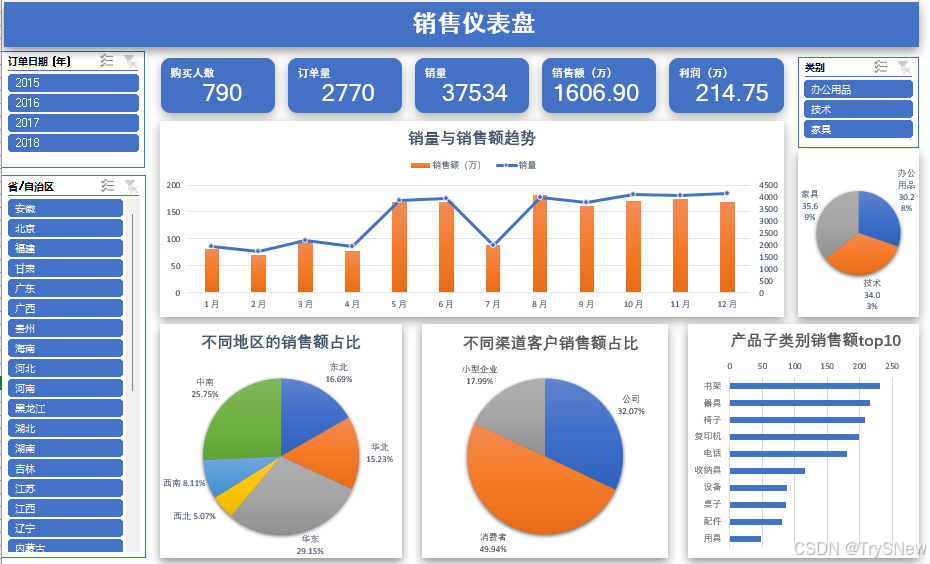
某公司线上销售办公用品及部分家具,产品有3大类、17种,客户分布在不同的区域。假设希望通过真实的销售数据搭建可视化看板来直观了解总体销售情况。以下是销售系统导出的2015-2018年的销售数据,共计9959条数据,字段内容如下。
本次数据集来自UCI机器学习库中的电信流失数据集。该数据集是在 12 个月内从伊朗某电信公司数据库中随机收集的。通过收集客户数据、清洗、选择关键特征、建立预测模型、评估和优化模型等步骤,帮助企业了解客户行为模式,并采取相应措施来最大程度地减少流失、提高留存。