




- @m0_58297458
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Sequential模型的基本组件有5个部分:model.add()、model.compile()、model.fit()、model.evaluate()、model.predict()。将输入层、隐藏层、输出层按需等添加进Sequential容器,Sequential模型的核心操作是添加layers(图层),是简单的线性、从头到尾的顺序结构。tensor:可选参数,若指定,该层将使用这个张量

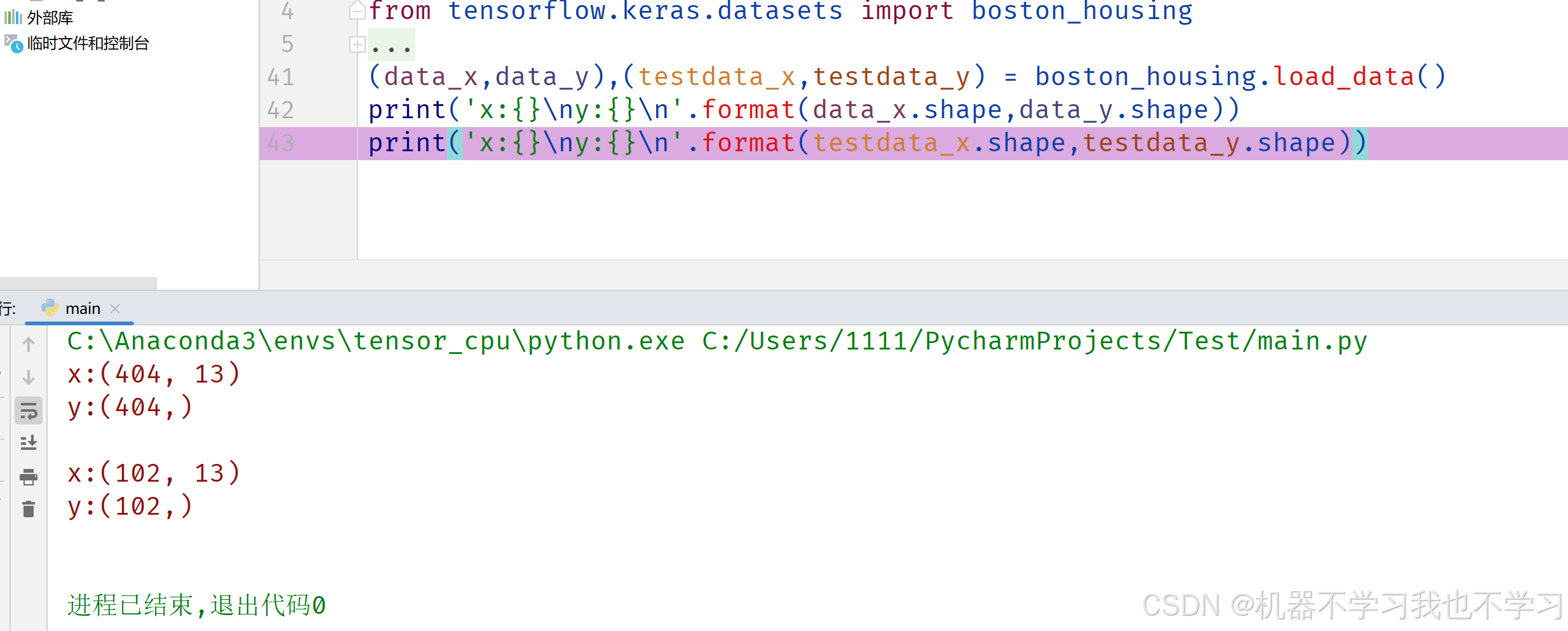
加载完成后,数据需调整格式,转换为Dataset对象,才能在tensorflow中流转,使用tensorflow中提供的各种便捷,使用tf.data.Dataset.from_tensor_slices(data)将data转为Dataset对象。使用load_data()函数加载,然后划分为训练数据集(data_x,data_y)及测试数据集(testdata_x,testdata_y),并输出
使用 train_test_split 函数,将所有图像划分为训练集train_imgs和测试集test_imgs,所有标签划分为训练集标签train_labels和测试集标签test_labels。save_root=os.path.join(new_data_root, "train"),# 目标:./new_data/train/类别名/save_root=os.path.join(new_
tf.keras.layers.Dense(256, activation="relu", kernel_regularizer=tf.keras.regularizers.l2(0.001)),# 添加全连接层,256个神经元,使用ReLU激活函数,kernel_regularizer添加L2正则化,进一步防止过拟合。tf.keras.layers.Dropout(0.4),# 添加Dropou
plt.plot(history.history['val_accuracy'], label='验证准确率')plt.plot(history.history['accuracy'], label='训练准确率')plt.plot(history.history['val_loss'], label='验证损失')plt.plot(history.history['loss'], label='
本文介绍了手势识别任务的数据预处理流程,主要包括:1)使用h5py库加载HDF5格式的数据集;2)通过train_test_split分割训练集和验证集;3)图像归一化处理将像素值缩放到[0,1]区间;4)标签转换为one-hot编码;5)创建数据增强生成器,仅采用不影响手势类别识别的变换(如水平翻转、微小平移)。数据预处理过程严格保持训练集、验证集和测试集的一致性,并打印关键数据形状进行验证,为
一份《数据报告》:记录数据来源、清洗过程、预处理方法、数据集划分结果;可直接使用的数据文件:如处理后的图像文件夹(train/val/test 子文件夹)。深度学习项目的 “前期准备”(需求 + 数据)往往占总耗时的 50% 以上,对后续项目质量影响很大。
update_freq: 常用的三个值为’batch’ 、 ‘epoch’ 或 整数。当使用 ‘batch’ 时,在每个 batch 之后将损失和评估值写入到 TensorBoard 中。使用回调函数可以在每次 批训练之后生成日志,以便监控指标、定期保存模型或保存最优模型、尽早停止训练等。histogram_freq: 对于模型中各个层计算激活值和模型权重直方图的频率。write_grads: 是
