




- @m0_58024423
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录聚类分析的定义及原理聚类方法及其在SPSS中的实现总结及拓展聚类分析的定义及原理1.定义所谓物以类聚、人以群分。聚类分析,即是基于研究对象的特征,将他们分门别类,以让同类别的个体之间差异相对小、相似度相对大,不同类别之间的个体差异大、相似度小。聚类分析是一种探索性分析方法,与判别分析不同,聚类分析事先并不知道分类的标准,甚至不知道应该分成几类,而是会根据样本数据的特征,自动进行分类。...
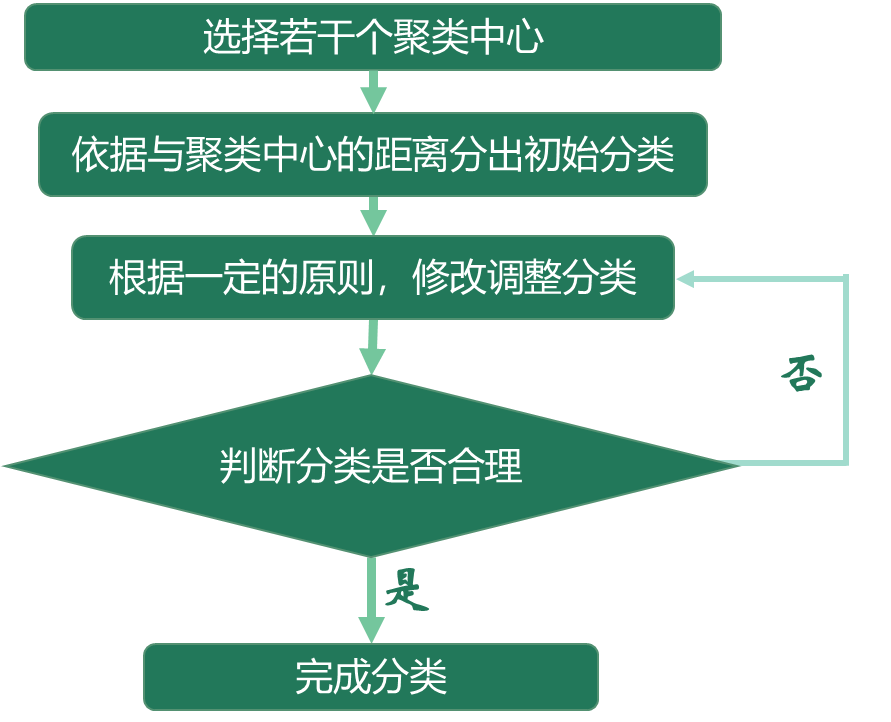
目录聚类分析的定义及原理聚类方法及其在SPSS中的实现总结及拓展聚类分析的定义及原理1.定义所谓物以类聚、人以群分。聚类分析,即是基于研究对象的特征,将他们分门别类,以让同类别的个体之间差异相对小、相似度相对大,不同类别之间的个体差异大、相似度小。聚类分析是一种探索性分析方法,与判别分析不同,聚类分析事先并不知道分类的标准,甚至不知道应该分成几类,而是会根据样本数据的特征,自动进行分类。...
import matplotlib.pyplot as pltmy_dpi = 96fig, axs = plt.subplots(2, 2, figsize=(480 / my_dpi, 480 / my_dpi), dpi=my_dpi,sharex=False,# x轴刻度值共享开启sharey=False,# y轴刻度值共享关闭)#.
前言:随机森林填补缺失值的优点:(1)随机森林填补通过构造多棵决策树对缺失值进行填补,使填补的数据具有随机性和不确定性,更能反映出这些未知数据的真实分布;(2)由于在构造决策树过程中,每个分支节点选用随机的部分特征而不是全部特征,所以能很好的应用到高维数据的填补;(3)随机森林算法本身就具有很好的分类精度,从而也更进一步确保了得到的填补值的准确性和可靠性。废话不多说,直接上python代码:首先导