




- @m0_54713489
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Scroll作为可滚动的容器类组件,它最多包含一个子组件,Scroll而。
Scroll作为可滚动的容器类组件,它最多包含一个子组件,Scroll而。
大语言模型微调中训练RL模型最常用的优化方法是近端优化算法(Proximal Policy Optimization, PPO)。RL损失函数本质上是在奖励模型打分、人类偏好约束和通用能力三者间平衡,既要输出优质答案,也不能偏离原有分布太远,还要保持通用能力。(3) 生成调优模型(Tuned Language Model, RL Policy)(2) 初始语言模型(Base Language Mo
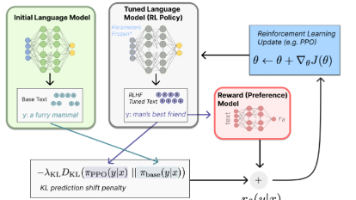
大语言模型微调中训练RL模型最常用的优化方法是近端优化算法(Proximal Policy Optimization, PPO)。RL损失函数本质上是在奖励模型打分、人类偏好约束和通用能力三者间平衡,既要输出优质答案,也不能偏离原有分布太远,还要保持通用能力。(3) 生成调优模型(Tuned Language Model, RL Policy)(2) 初始语言模型(Base Language Mo
大语言模型(LLMs)。这类模型通常基于 Transformer decode-only 架构,在海量无标注文本语料上进行预训练。其核心预训练任务是预测下一个 token,这一目标驱动着模型的学习过程。Lt1∑NlogPθxt1∣x1t其中,P代表大语言模型,θ是模型的可训练参数。训练目标是在给定前序 tokensx1tx1⋯xt的条件下,最大化下一个 tokenxt1出现的概率。

大语言模型微调中训练RL模型最常用的优化方法是近端优化算法(Proximal Policy Optimization, PPO)。RL损失函数本质上是在奖励模型打分、人类偏好约束和通用能力三者间平衡,既要输出优质答案,也不能偏离原有分布太远,还要保持通用能力。(3) 生成调优模型(Tuned Language Model, RL Policy)(2) 初始语言模型(Base Language Mo
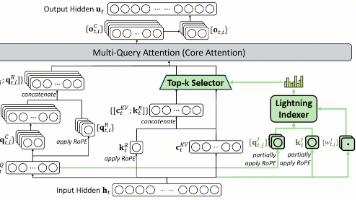
DeepSeek-V3.2 技术报告中提到的是一种旨在提升上下文处理效率的稀疏注意力机制。
笔者在学习时发现网上很多方法实现的Text组件展开/收起效果比较复杂,且涉及到计算,于是查阅了相关文档,尝试通过Text组件自带的属性函数实现需求,以下为解决方案:

运用Scroll组件事件onDidScroll实现实时监控水平方向滚动偏移量,并且提供了onDidScroll正常使用说明
如何使用HarmonyOS NEXT自带的图标库,并且附上导入外部字体图标ttf的方法