




- @m0_51704901
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
角色扮演语言智能体已经被用于模拟各种类型的人设,包括人口统计学意义上的群体人物、虚构角色以及日常个体。这类技术也催生了许多应用,例如角色聊天机器人、电子游戏中的智能体,以及人类的数字分身等。本文研究的是面向既定角色的角色扮演语言智能体。相比于简单地描绘个体特征或刻板印象,这是一项更加重要且更具挑战性的任务。具体而言,角色扮演语言智能体需要忠实地对齐角色复杂的背景,并捕捉其细腻的人格特征。为了构建有
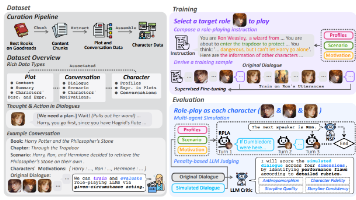
关于人格动态的心理学研究,包括,已经表明:人的行为并不是由固定人格静态决定的,而是由特定场景下被激活的人格属性所产生的。与此类似,大语言模型也应该能够在不同上下文场景中,动态识别哪些人设属性与当前场景相关,并在生成时遵循预先定义的人设档案。作者将这种能力称为,即“人设遵循能力”。和。包括直接提示、上下文学习,以及检索增强生成(RAG)这类方法的核心机制依赖于模型对 prompt 文本的语义识别,模
关于人格动态的心理学研究,包括,已经表明:人的行为并不是由固定人格静态决定的,而是由特定场景下被激活的人格属性所产生的。与此类似,大语言模型也应该能够在不同上下文场景中,动态识别哪些人设属性与当前场景相关,并在生成时遵循预先定义的人设档案。作者将这种能力称为,即“人设遵循能力”。和。包括直接提示、上下文学习,以及检索增强生成(RAG)这类方法的核心机制依赖于模型对 prompt 文本的语义识别,模
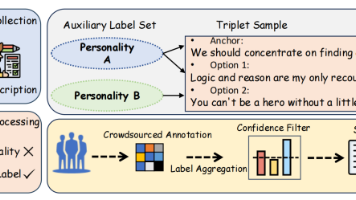
人格是心理学中的一个关键概念,它强调个体在思想、情感和行为方面的差异。随着自然语言处理技术的发展,自动人格识别受到了广泛关注。因为其在心理健康评估、角色扮演以及个性化推荐系统等方面具有广泛应用。为了在AI模型中表达人格,当前方法主要采用传统的监督学习范式。研究者会收集“语料-人格”数据集来训练预测模型。其中每个样本由多条句子组成,并被组织为一个“文本包(bag)”。人格标签以离散形式由人工进行标注
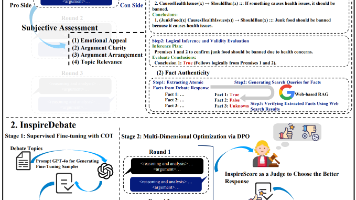
随着大语言模型(LLMs)的快速发展,与辩论相关的任务——例如论点质量评估和辩论过程模拟——已经取得了显著进展。然而,现有辩论评估方法主要集中在对单个论点进行评估(Deshpande 等,2024),并且严重依赖主观性评价,缺乏对整个辩论过程进行全面评估的能力为了解决这些相互关联的挑战,我们提出了一个由两个核心组成部分构成的框架:(1):一种新的评估体系,构建了一个多维度的评估架构,包括四个主观指
大语言模型(LLMs)已经在教育领域中被广泛用于各种智能教学任务,例如自动评分、问答系统、教学助理等。这些都是“任务特定(task-specific)”的应用,即每个模型通常完成一个单一的教学任务。目前仍缺乏一种多智能体(multi-agent)协作框架,能够在真实用户参与的虚拟课堂环境中模拟教师与学生的互动。模拟性能:多智能体课堂能否逼真地模拟师生实时互动?学习体验:学生是否能在其中获得真实的“
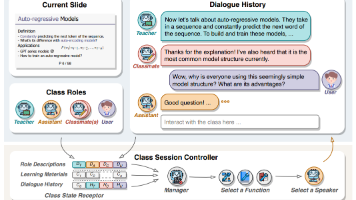
大语言模型(LLMs)已经在教育领域中被广泛用于各种智能教学任务,例如自动评分、问答系统、教学助理等。这些都是“任务特定(task-specific)”的应用,即每个模型通常完成一个单一的教学任务。目前仍缺乏一种多智能体(multi-agent)协作框架,能够在真实用户参与的虚拟课堂环境中模拟教师与学生的互动。模拟性能:多智能体课堂能否逼真地模拟师生实时互动?学习体验:学生是否能在其中获得真实的“
1.角色设定与对话不匹配(Profile-Diaglogue Bias)如果对话语料与角色预设档案(profile)不一致,会在训练中引入偏差,使模型难以按照角色档案行为。2.缺乏精细对齐(Fine-Grained Alignment)单一的对话训练任务无法将对话与角色特质进行细粒度对齐。训练过程无法捕捉角色特质在具体语句中的体现,限制了模型理解和表达角色复杂特质的能力。