




- @m0_38097087
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
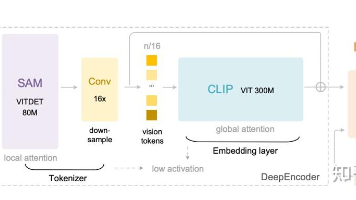
研究动机:LLM 处理超长上下文时计算与显存成本会随序列长度急剧上升。DeepSeek-OCR 提出把长文本转为高分辨率图像,再用视觉 token替代海量文本 token,从而显著降低成本。总体架构:一个DeepEncoder(视觉编码器)+ 一个3B MoE 解码器。DeepEncoder 以窗口注意力 + 16×卷积压缩 + 全局注意力串联,既能吃高分辨率,又能把视觉 token 压到很少;解
通过前边的 YOLO 检测器和文本编码器分别得到了特征图像和词向量,那么如何实现二者的融合,以达到开放词汇目标检测的目的?YOLO-World 中提出了新的网络架构RepVL-PAN(Re-parameterizable Vision-Language Path Aggregation Network),它通过融合视觉信息和语言信息来提升检测性能并兼顾实时推理。
yolo系列:从yolov1到yolov13。
通过前边的 YOLO 检测器和文本编码器分别得到了特征图像和词向量,那么如何实现二者的融合,以达到开放词汇目标检测的目的?YOLO-World 中提出了新的网络架构RepVL-PAN(Re-parameterizable Vision-Language Path Aggregation Network),它通过融合视觉信息和语言信息来提升检测性能并兼顾实时推理。
通过前边的 YOLO 检测器和文本编码器分别得到了特征图像和词向量,那么如何实现二者的融合,以达到开放词汇目标检测的目的?YOLO-World 中提出了新的网络架构RepVL-PAN(Re-parameterizable Vision-Language Path Aggregation Network),它通过融合视觉信息和语言信息来提升检测性能并兼顾实时推理。
DINOv2 这篇工作可以直接理解成:把 DINOv1、iBOT 等一堆自监督技巧「凑成一个最强配方」,然后在「超大干净数据集 + 超大 ViT」上把配方拉满,从而得到一套「啥都能用、跨任务泛化很强」的视觉基础特征(visual foundation features)。本文尽量站在工程实践视角来讲清楚:在第一篇里我们已经说过:DINOv1 的核心是 Student–Teacher 自蒸馏 + 多
1 本代码功能用多目标粒子群算法(mopso)寻找pareto最优解集2 算法介绍2.1 简单步骤:(1)初始化群体粒子群的位置和速度,计算适应值(2)根据pareto支配原则,计算得到Archive 集(存放当前的非劣解)(3)计算pbest(4)计算Archive集中的拥挤度(5)在Archive集选择gbest(6)更新粒子的速度、位置、适应值(7)更新Archive集(还要注意防止溢出)(