




- @lutlx20010913
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
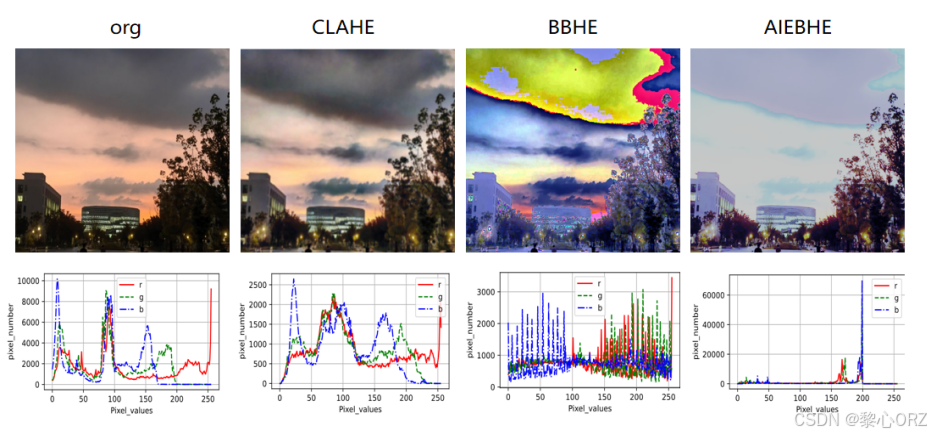
随着信息时代的到来,多媒体技术已经进入千家万户,视频图像作为感知世界的重要载体,已经成为人们不可或缺的信息资源。然而受到成像设备和照明条件限制,图像视频捕获过程中,由黑暗环境下带来的低对比度和成像设备带来的噪声往往极大限制了图片的质量,从而造成信息损失,同时降低人的感观体验,低光的照明环境同时也影响着计算机下游任务如(目标检测,人脸识别,语义分割)等,人的感知系统很难在有限的光照下捕获到图片的有效
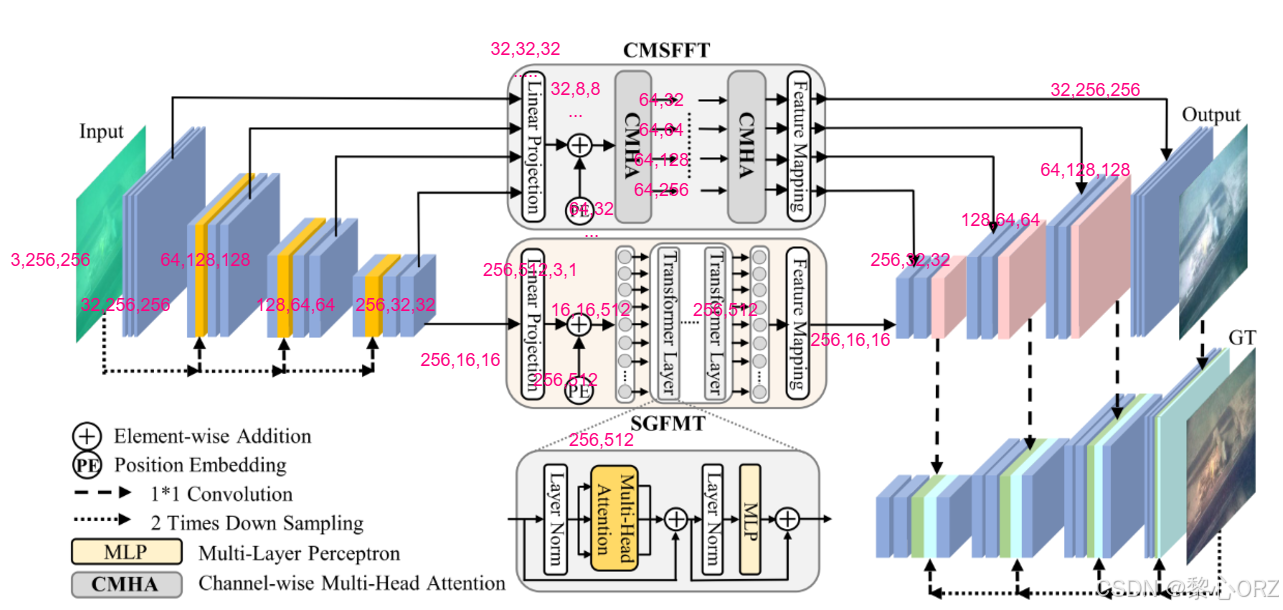
本文讲述了一种水下图像增强的U形Transformer,本文发布在arXiv、SpringerLink、IEEE Xplore 等多个平台上,本文作者为 Lintao Peng(彭林涛)、Chun Li Zhu(朱春丽)和 Liheng Bian(边丽衡)。其中,彭林涛是北京理工大学的博士生,他的研究兴趣主要集中在计算成像和传感方面,特别是基于深度学习的复杂环境成像和传感技术,同时也在研究各种新型
本文发表于期刊IEEE Signal Processing Letters ,发表时间为 2023年 11 月。第一作者张东卫:中共党员,博士,河南科技学院信息工程学院校聘教授。长期从事低可视性图像增强、智慧农业、深度学习等方面的研究。翻译由于光的吸收和散射,水下采集的图像常常面临严重的质量退化问题。在本文中,提出通过分段颜色校正和双重先验优化对比度增强来解决上述问题。

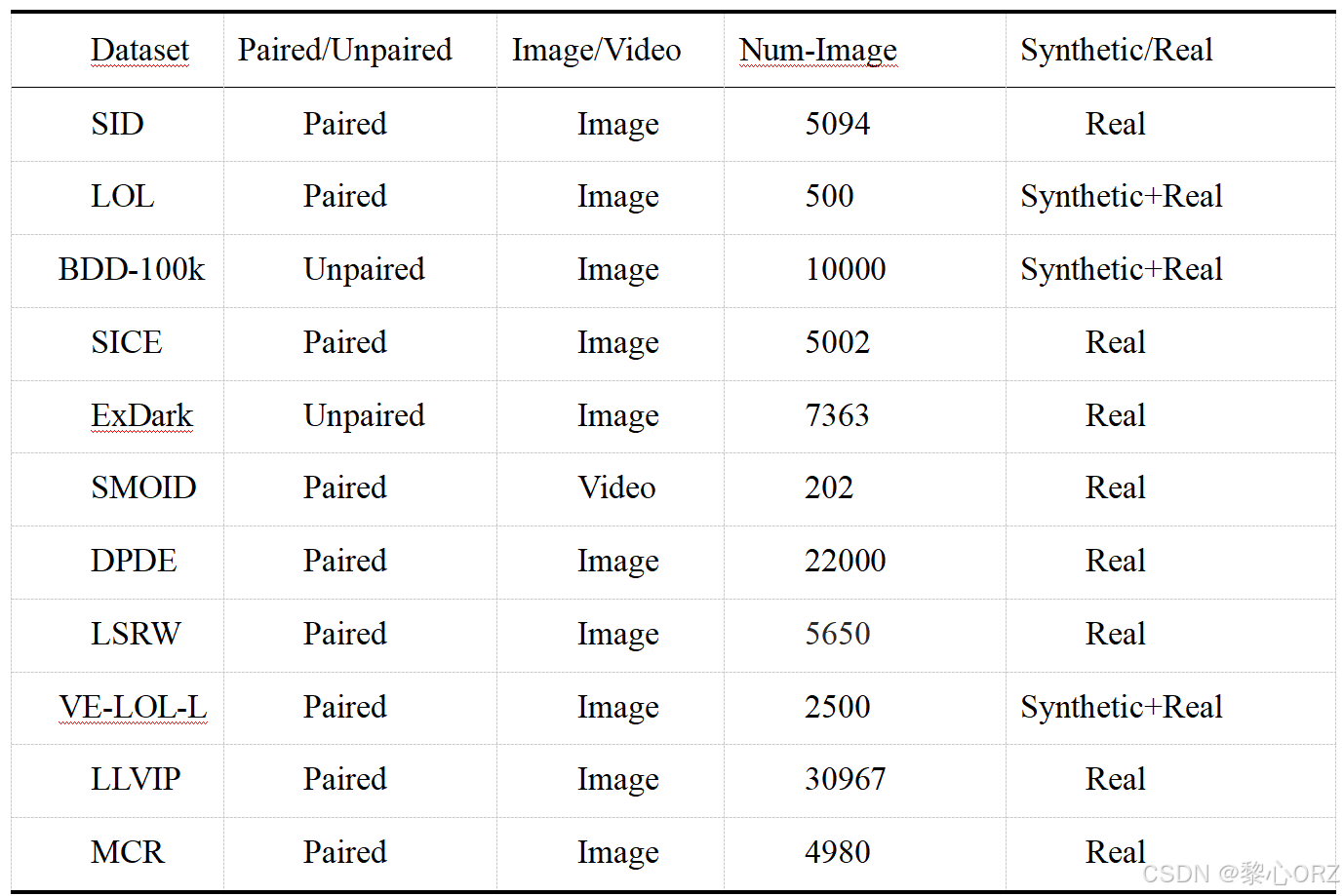
早期的数据集通常用于传统和基于模型的方法,这对数据的数量和质量没有严格的要求,随着深度学习在低光图像增强领域的发展,一个优质的低光图像增强通常需要庞大且成对的数据集,首先得足够庞大,能够全面反映真实世界里问题、图像及概念的各种变化。接下来,我们会列举一些现有的典型数据集
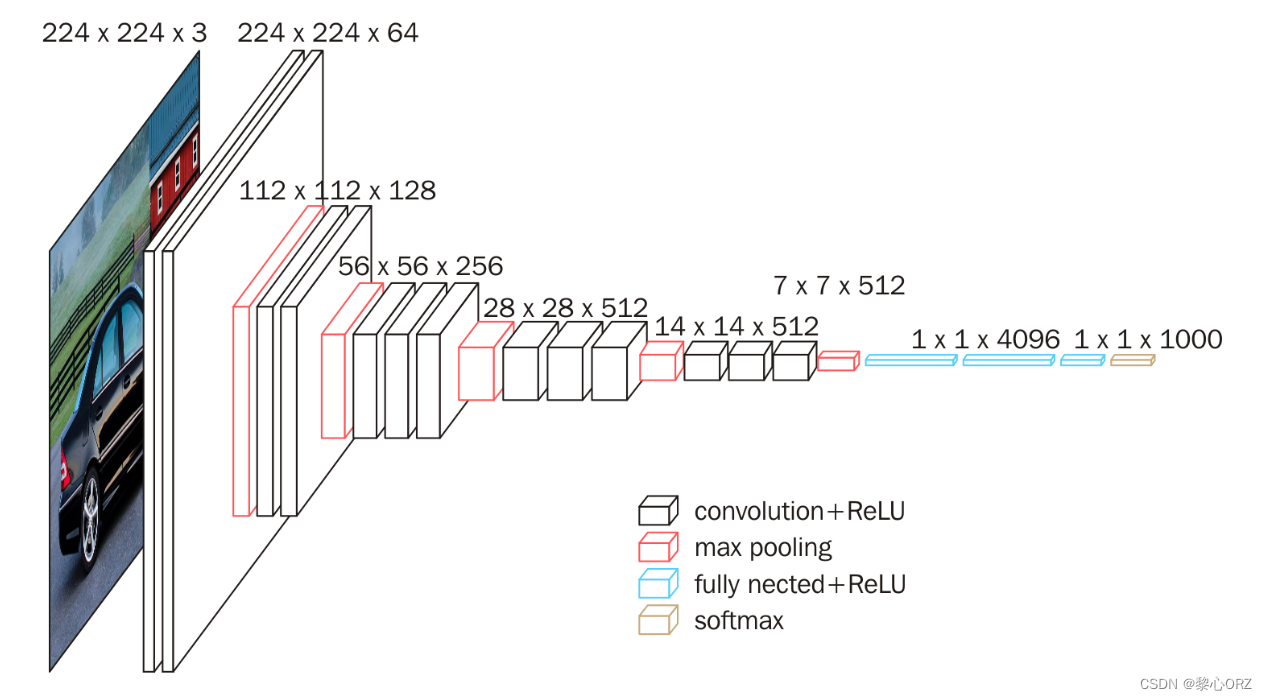
VGG16是一种卷积神经网络(Convolutional Neural Network,CNN),是由Simonyan和Zisserman于2014年提出的用于图像识别任务的其中一种网络结构。VGG16网络包含13个卷积层和3个全连接层,在ImageNet数据集上表现出色,并成为后来CNN结构的基础。下面对VGG16网络的参数和FLOPs进行计算。
早期的数据集通常用于传统和基于模型的方法,这对数据的数量和质量没有严格的要求,随着深度学习在低光图像增强领域的发展,一个优质的低光图像增强通常需要庞大且成对的数据集,首先得足够庞大,能够全面反映真实世界里问题、图像及概念的各种变化。接下来,我们会列举一些现有的典型数据集