




- @liuxiaoer1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行(Execution) 三大过程。其中Spark SQL 解析和优化如下图Parser模块:未解析的逻辑计划,将SparkSql字符串解析为一个抽象语法树/AST。语法检查,不涉及表名字段。

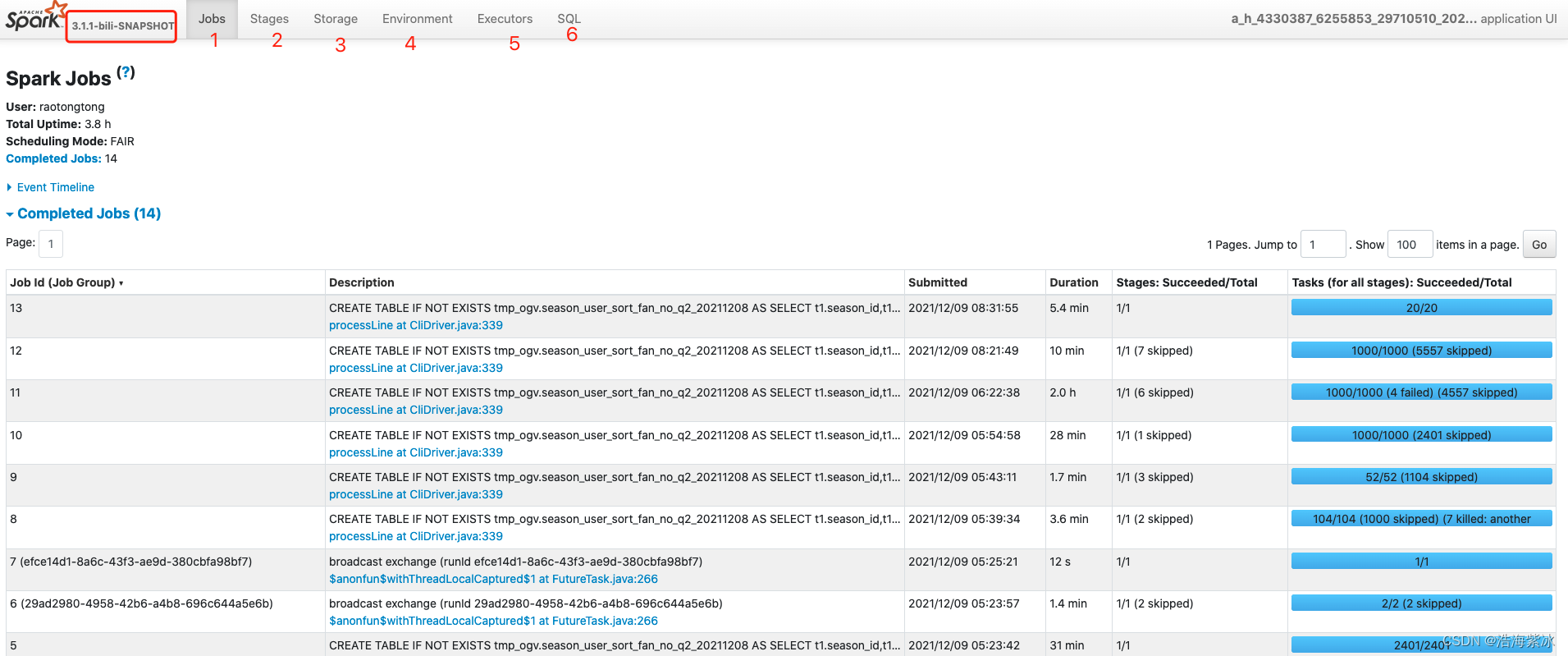
注意看到stage 19-24 是 跳过了, 原因是spark shuffle 的数据会写到磁盘固化,当上游当上游stage(19-24)和之前执行过的stage 相同时,可以直接用之前的结果.正在运行中的任务有 thread dump ,跟踪task 的执行过程,目前只能点开 driver 的节点, executor 节点 点击不开.每个状态的stage 数量 (active, pending,
Kafka的两个topic,topic1 为用户下单明细记录(包含订单基本信息),topic2为下单渠道记录(包含下单来源和渠道内容设备相关的信息) ,要求实时统计每分钟内所有订单下的渠道来源分布详情。具体做法是1.双流关联得到每个订单的渠道信息明细interval join2.根据渠道维度汇总聚合数据。但是在实时流数据输出的结果和离线订单有gap,发现双流关联后中间结果数据有重复订单数据。
问题:统计活跃用户的近7天、30天留存率?这个是数据仓库开发同学基本都会遇到的问题,属于留存类问题,实现方式也有很多种类,但是在大数据场景下的效率差距很大,因此整理自己写过四种输出留存的方式和对比下优劣。