




- @liu1983robin
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
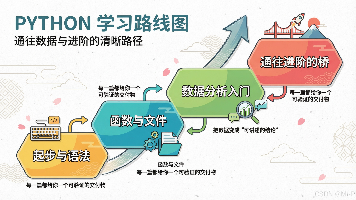
这篇Python学习专栏采用"先交付再系统化"的实践教学法,通过20篇教程帮助零基础学习者快速入门。每篇教程聚焦一个可验证的交付物(如文件批处理工具、数据清洗报告等),包含真实问题、最小可行结果、复用模板和常见问题解答。学习路径从基础语法到数据分析循序渐进,强调通过积累可运行代码模板库来突破入门门槛。专栏还指出了进阶学习可能遇到的三大瓶颈,并推荐了付费进阶课程。学习方法强调&q
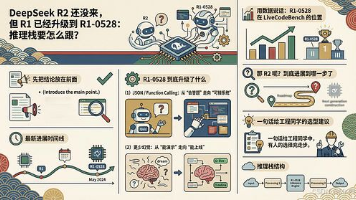
摘要: DeepSeek R2 尚未发布,但 R1 已升级至 R1-0528,支持 JSON 输出、函数调用,并优化了基准性能与幻觉问题。当前 API 主力模型仍为 V3.2,但 R1-0528 更适合结构化任务与工具调用场景。R2 因性能与芯片问题延迟,建议优先升级推理栈至 R1-0528 或 V3.2,并适配接口与评测体系。工程选型需结合需求:任务执行选 JSON/函数调用,Agent 工作流
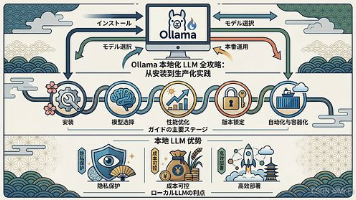
本文介绍了如何将Ollama本地化部署大型语言模型(LLM)的完整工程化方案。文章首先提出两种部署路线:轻量快速的CLI方式和生产稳定的工程化路线,强调真正的挑战在于将本地AI从实验转变为可交付产品。接着详细阐述了本地部署的核心价值,包括隐私保护、成本控制、离线工作等优势,并提供了从环境准备到前端集成的完整工程链路图。文章重点讲解了工程化部署的三个关键环节:版本锁定、自动化脚本和容器化方案,并给出
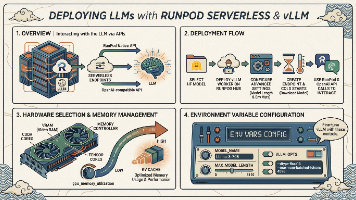
本文介绍了如何利用RunPod Serverless和vLLM快速部署开源大语言模型。主要内容包括:1) 通过RunPod控制台直接部署vLLM Worker,支持Hugging Face模型;2) 关键配置参数如显存管理(GPU_MEMORY_UTILIZATION)和上下文长度(MAX_MODEL_LEN)的优化建议;3) 两种API调用方式(RunPod原生和OpenAI兼容接口);4) 常
OpenClaw作为2026年爆发的AI Agent框架,凭借模块化设计、多模型支持和强化学习能力,正在重塑AI应用开发范式。本文从架构设计到实战部署,详细介绍了在Windows环境下搭建OpenClaw系统的全流程,包括硬件配置、安装指南、智谱GLM-4模型集成,以及强化学习调优等关键技术。通过高校智能助教系统的案例,展示了如何实现从基础对话到自主进化的完整AI Agent闭环。文章特别强调GR

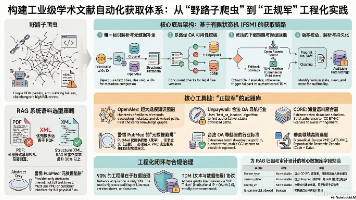
本文主张告别爬虫,用有限状态机(FSM)搭建文献获取:以DOI唯一标识驱动,先拉元数据,再按OA→TDM回退链路取文;下载PDF/XML后做版本与许可校验并入库。强调“发现≠获取”、优先XML/HTML,并以license/source/version/timestamp做审计追溯,避免侵权与失效。
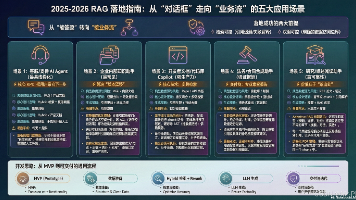
本文从工程实践角度剖析了当前最具商业价值的五大RAG应用场景,揭示了传统方法的三大致命漏洞:语义相似度陷阱、权限裸奔问题和黑盒生成风险。文章指出2025年工业级RAG的核心KPI已转变为检索可控性和权限可控性,并重点分析了客服AI Agent、企业知识助手和代码库Copilot三大深水区应用。
OpenClaw作为2026年爆发的AI Agent框架,凭借模块化设计、多模型支持和强化学习能力,正在重塑AI应用开发范式。本文从架构设计到实战部署,详细介绍了在Windows环境下搭建OpenClaw系统的全流程,包括硬件配置、安装指南、智谱GLM-4模型集成,以及强化学习调优等关键技术。通过高校智能助教系统的案例,展示了如何实现从基础对话到自主进化的完整AI Agent闭环。文章特别强调GR
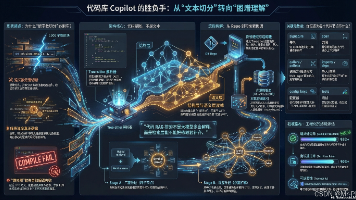
传统代码检索系统因采用“字符串暴力切分”而频繁失效,根源在于忽视了代码的结构化特性。本文提出基于AST语法树的检索范式,通过Tree-sitter工具实现精准代码解析,建立包含符号引用、调用链、配置依赖等元数据的知识图谱。相比文本切分方案,该方法能提升40%的代码生成准确率,解决依赖缺失、语义断裂等核心痛点。关键技术包括:以函数/类为最小检索单元、构建多跳依赖关系图谱、实现代码与配置的关联索引。该
《AI 时代的学术入门:文献综述实践指南》面向初学者,提供一套可复用、可落地的文献综述工作流,避免“堆论文却写不出观点、引用链易断”的常见困境。指南以 Step 1 检索、Step 2 筛选、Step 3 入库、Step 4 提取、Step 5 生成串起全流程,强调“AI 负责加速,你负责判断与把关”。读者将学会用关键词金字塔构建检索式、用规则与相似度做筛选、用 Zotero 沉淀文献资产,并用
