
写文章




- @ldy_lzy
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
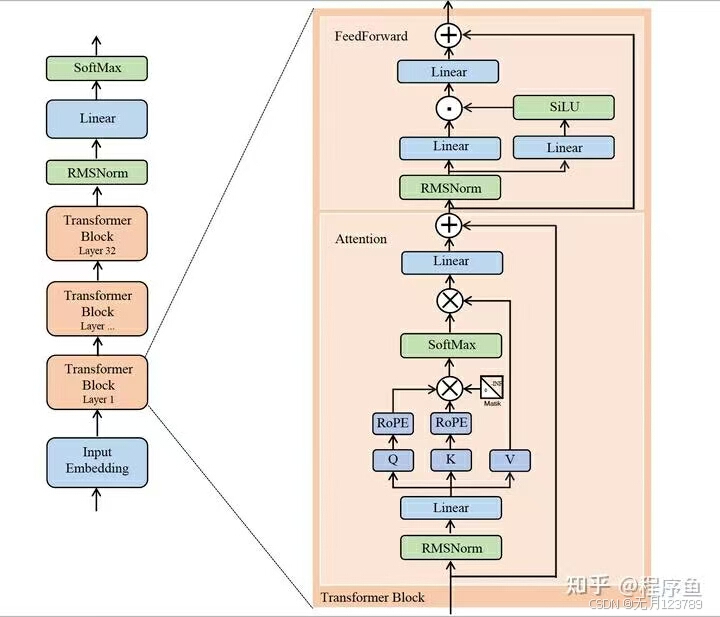
论文精读(2)——精读DeepSeek技术报告系列
目前deepseek大火,很多文章也对其团队发出的技术报告进行了详细的解读和分析,但更需要的是从头开始一步一步展示deepseek发展过程,而这里就是他们的第一篇技术报告。
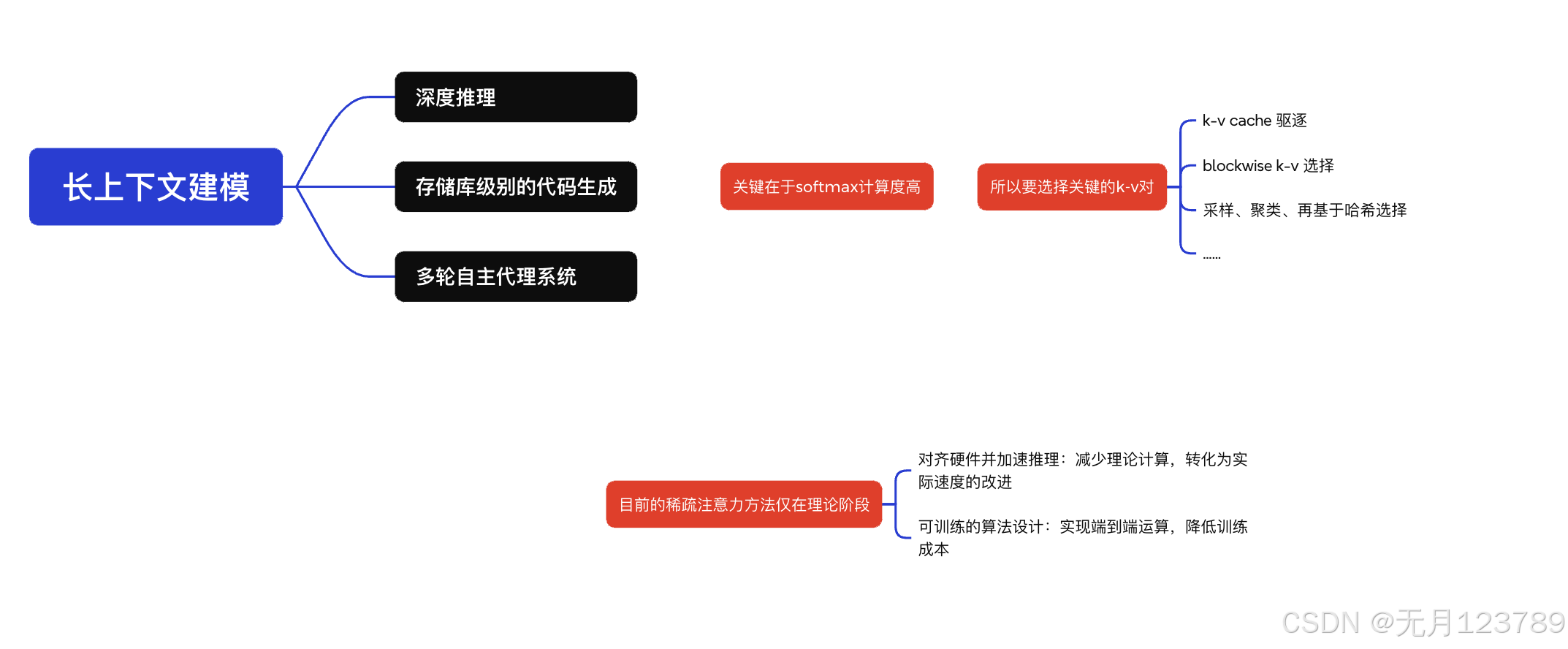
论文精读(5)——NSA 论文详解
目前主流的架构都在处理大模型长上下文的建模问题,因为这会导致Transformer内存太大;前面我所总结的的论文精读:Titans曾提到其中一个方向是稀疏注意力的方法,而正巧的是NSA和MoBA都提到了这一技术
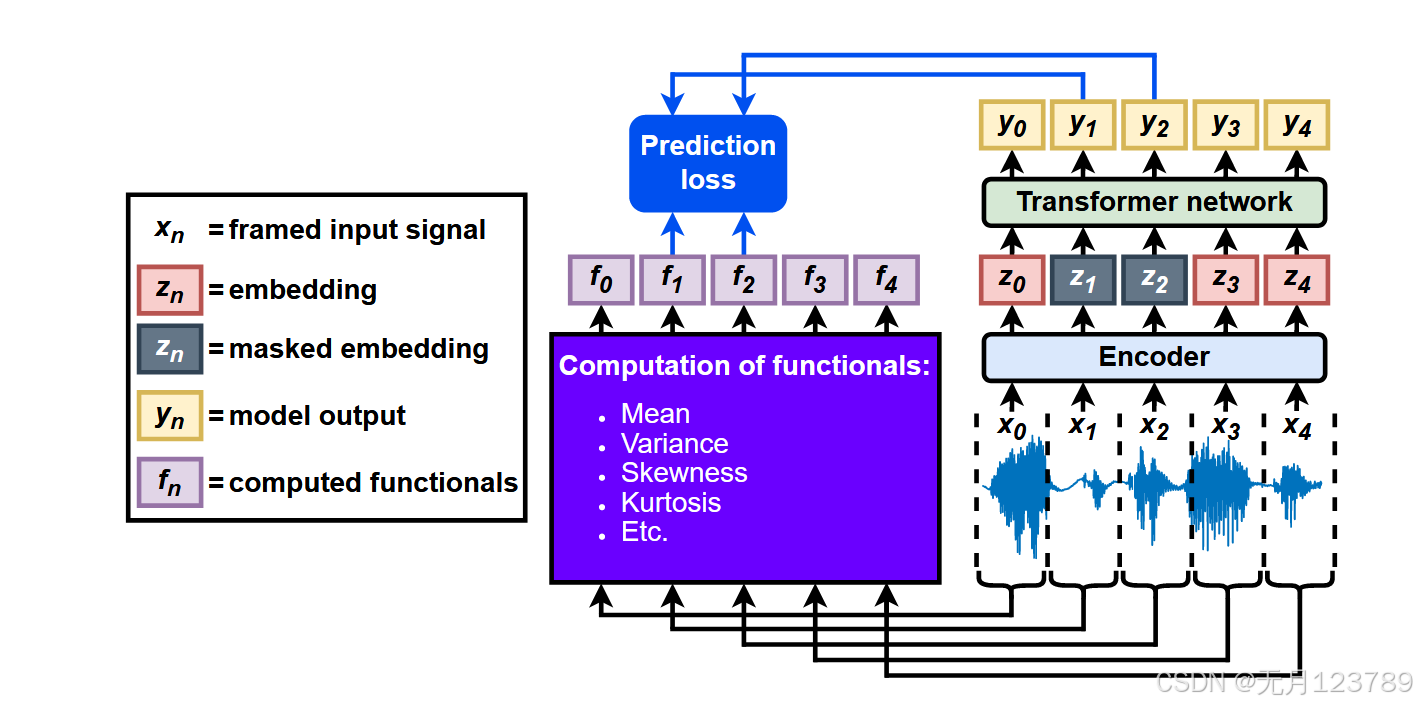
论文精读(1)
论文大致介绍了表征坍缩(representation collapse),即模型输出一个持续的输入不变的特征表示。所采用的方法是不在高维重构信号,而是预测嵌入(embedding)层;并对时间序列的统计值的泛函做预测。
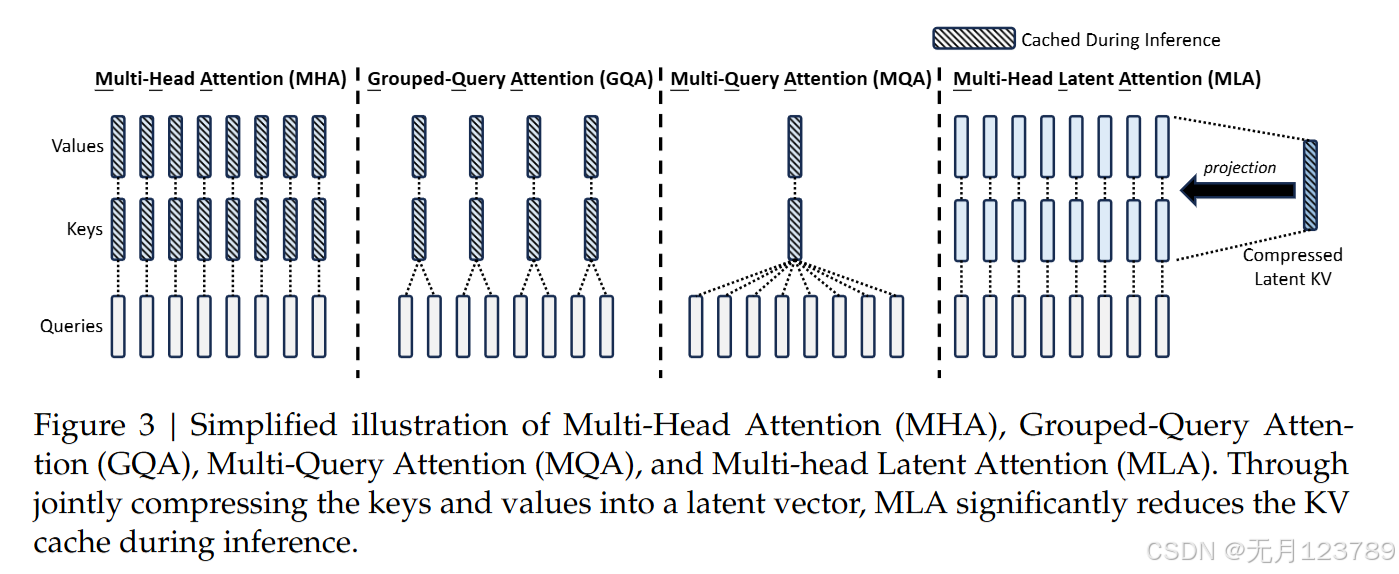
论文精读(3)——精读DeepSeek技术报告系列
关于Deepseek-V2版本技术点的创新确实很多,因此会发布三篇文章来深入浅出的讲解。这篇主要串一下整体的流程并详细讲解第一个技术创新:Multihead latent Attention(MLA);个人认为技术创新一定有规律遵循,就好比搭积木一点一点搭起来的,每理解清楚一层再走到下一层才会更加坦然
论文精读(2)——精读DeepSeek技术报告系列
目前deepseek大火,很多文章也对其团队发出的技术报告进行了详细的解读和分析,但更需要的是从头开始一步一步展示deepseek发展过程,而这里就是他们的第一篇技术报告。
到底了