




- @l963852k
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过以上步骤,你可以在 Conda 虚拟环境中成功安装并运行 Jupyter Lab。

PPO是actor_critic结构,需要两个网络一个actor网络,一个critic网络。这两个网络可以共享参数也可以不共享参数。habitat中的ppo在特征提取阶段采用了参数共享,然后分出了两个头。"""agent: PPO上面的代码可以看出self.actor_critic是NetPolicy类型,而NetPolicy类在中定义。在中的方法中......定义了self.actor_crit
PPO算法的原理解读以及代码实现
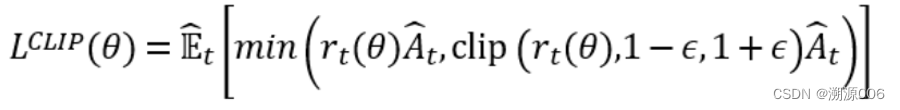
PPO是基于策略的强化学习,本文开始讲基于策略的强化学习,本文主要是理论部分

PPO是actor_critic结构,需要两个网络一个actor网络,一个critic网络。这两个网络可以共享参数也可以不共享参数。habitat中的ppo在特征提取阶段采用了参数共享,然后分出了两个头。"""agent: PPO上面的代码可以看出self.actor_critic是NetPolicy类型,而NetPolicy类在中定义。在中的方法中......定义了self.actor_crit
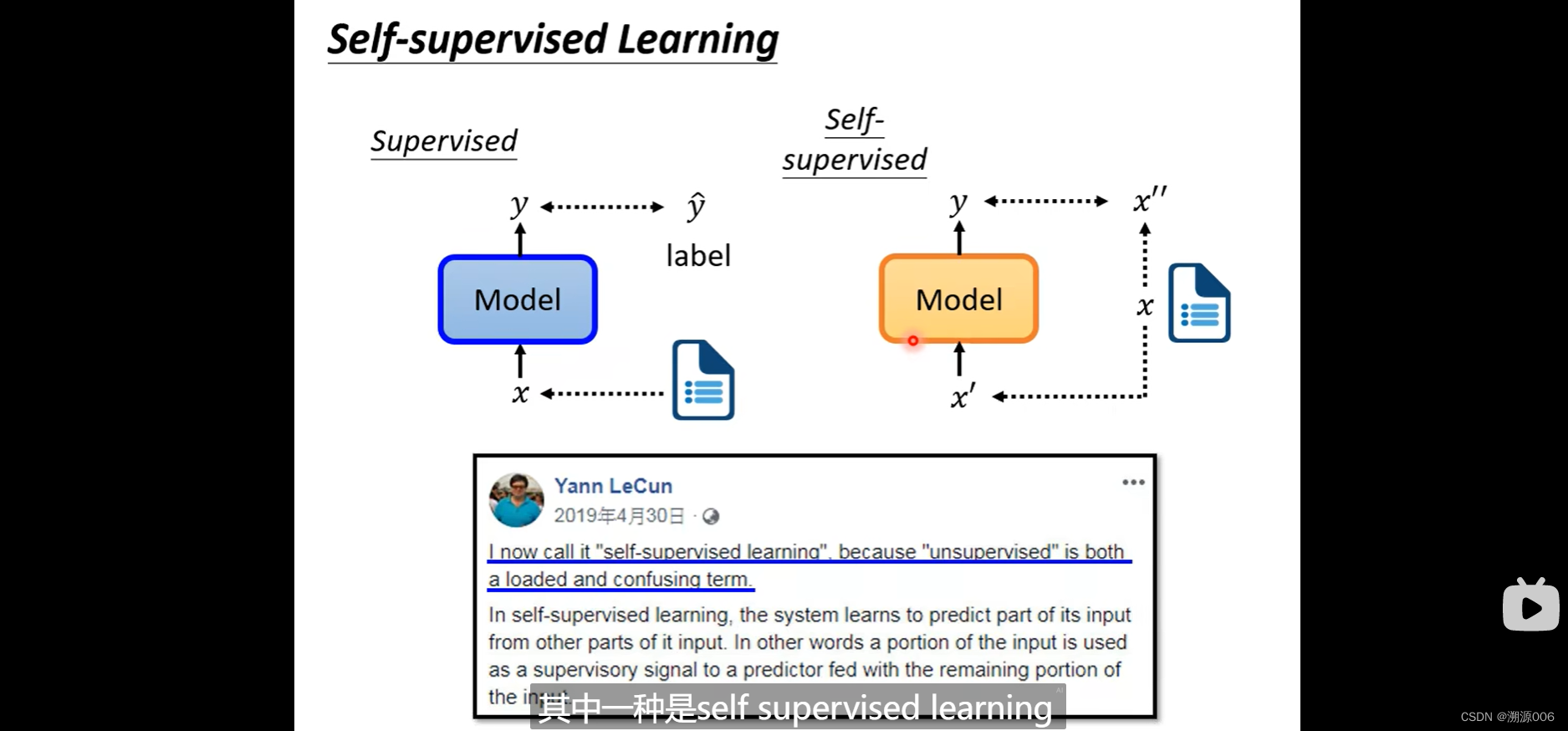
1)BERT是自监督的学习,不需要人工标注的标签,所以其实也是无监督学习的一种方式2)BERT的主干网络就是tranformer的encoder部分,所以BERT使用了self-attention的机制3)BERT主要采用完形填空的方式。就是输入一句话,随机遮住某个词,然后预测遮住的词。这种方式其实很好的考虑了上下文,或者说就是基于上下文的语境来表示词的意思。实验证明这种方式得到了一种很好的emb
讲最经典的DDPM。

经历了MiniMind-V1的低质量预训练数据,导致模型胡言乱语的教训,2025-02-05之后决定不再采用大规模无监督的数据集做预训练。进而尝试把匠数大模型数据集的中文部分提取出来,清洗出字符<512长度的大约1.6GB的语料直接拼接成预训练数据,hq即为high quality(当然也还不算high,提升数据质量无止尽)。文件数据格式为{"text": "如何才能摆脱拖延症?治愈拖延症并不容易

例如,如果用户想修改文本解码器的某一层,可能需要通过遍历模型的子模块并替换相应的层。此外,针对qwen2-2B-VL这个模型,可能需要特定的处理,比如视觉特征的提取部分如何与文本部分结合,是否需要调整图像处理的分辨率或通道数等。嗯,用户的问题是关于如何使用transformers库加载预训练的大模型,比如qwen2-2B-VL,然后加载预训练参数,修改部分网络结构,再进行重新训练。最后,提醒用户在
