- @kiiy2
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
其中,原创大模型数量最少,做原创大模型需要有很强的技术积累,且要有持续的高投入,风险很大,因为一旦模型没有足够强的竞争力,这些大规模投入就打了水漂。大模型的价值需要商业化来证明,当市场上已经出现足够好的基础大模型,其他公司应该去挖掘新的价值点,比如大模型在不同领域的应用,或是中间层,比如帮大模型训练、数据处理、算力服务等。**2024年,AI大模型的发展会有几个相对确定的趋势:**一是融资热度下滑

看了那么多chatGPT的文章,作为一名不精通算法的开发,也对大模型心痒痒。但想要部署自己的大模型,且不说没有算法相关的经验了,光是大模型占用的算力资源,手头的个人电脑其实也很难独立部署。就算使用算法压缩后的大模型,部署在个人电脑上,还要忍受极端缓慢的计算速度以及与chatGPT相差甚远的模型效果。有什么办法能够部署属于我们自己的大模型呢?有编程基础:作为一个合格的程序员,这应该是必备素质。
不得不再提最近常被提起的一句话:如何与大模型共生我们在不断被迫接受着过量的信息和超出认知的技术革新,否则就会处于被革新的尴尬境地。与技术共生,与大模型共生:人在不断的驱赶下依然还有新的立足之地,这些新领地恰恰是技术延展出来的百年前的纺织工人的后代并不会接着做纺织,他可能是一名铁路工人。他的后代可能是个电报员之后会是电话员、股票代理以及现今担心被淘汰的白领们。只要新技术所带来的新领地足够大,总有你我

以情感分析任务为例,过去我们做此类任务的方式是对输入的文本去做一个分类任务,预测它情感的正向或者负向,更多的是一种判别式的方法。直接使用其 in content learning 的方式去做推荐的话,一个突出的问题是,GPT 是被高度安全优化过的,所以它很难去拒绝用户,也就是很难 say no,如果我们按照 point wise 的方式,给它一个 list,history,然后问它是不是要把这些推

在人工智能技术迅猛发展的今天,搭建本地专属的大模型不仅是提升数据安全和计算效率的明智选择,更是实现业务目标、控制成本和优化运营的重要战略。无论您是希望保护敏感数据、提升系统性能,还是追求自主控制和定制化解决方案,本地部署的大模型都能够为您的组织提供显著的优势。选择本地部署的大模型,可以提高系统的可靠性和连续性。选择本地部署的大模型,意味着组织可以对模型的管理、维护和更新拥有完全的自主控制权。通过本

目前,AI大模型已经在百行千业“落子不断”。教育、医疗、金融、电商、社交、图像、母婴等等行业都已经在大模型的的助力下探索新的发展可能。大模型浪潮汹涌,AI大模型工场试图从不同行业场景应用的角度,窥探大模型应用目前的落地状况。为此,我们对国内主流AI应用做了一些盘点与梳理,力图撇开表面的浮沫,看清大模型带来的新机会。

而面壁 MiniCPM-V 2.6 以 8B 参数,在综合性能上追赶上 GPT-4V 的同时,首次作为端侧模型,掀开单图、多图、视频理解三项多模态核心能力全面赶超 GPT-4V 的新格局,且均实现 20B 参数以下模型性能 SOTA。一个看似热衷环保的人,却把塑料瓶装水打开装进环保水壶……面壁认为,MiniCPM-V 2.6 之所以能实现从单一到全面的优势跃进,除了 Qwen2-7B 基座模型的性

根据媒体报道,在百度期间,李平和团队在深度学习算法、知识图谱和信息抽取、基于图的近似近邻检索和最大内积检索、树模型、哈希算法和近似近邻检索(ANN)算法、机器学习基础理论与方法、推荐和LTR技术、自然语言,大数据,和数据挖掘等方向发表了多篇国际顶会论文,并同百度凤巢广告,Feed流,搜索,百度知道,输入法,百度地图等多个团队展开深入合作,把研究成果应用于各项产品,产出显著效果,并能从实际问题中发展

大模型技术的核心价值是降低获取信息和技能的成本,提升个人办事效率,促进整体社会生产力的提升。小参数的大模型在具身机器人领域的应用,提升了自动化和智能化水平,实现高效、低功耗、低成本、低时延的处理和响应。未来的核心竞争点将不再是大模型的性能,而是能否结合自身业务和场景,将大模型训练出所需的功能。未来,大模型有望在基础科学领域取得突破性进展,实现信息智能、物理智能和生物智能的融合,成为科技发展的利器。
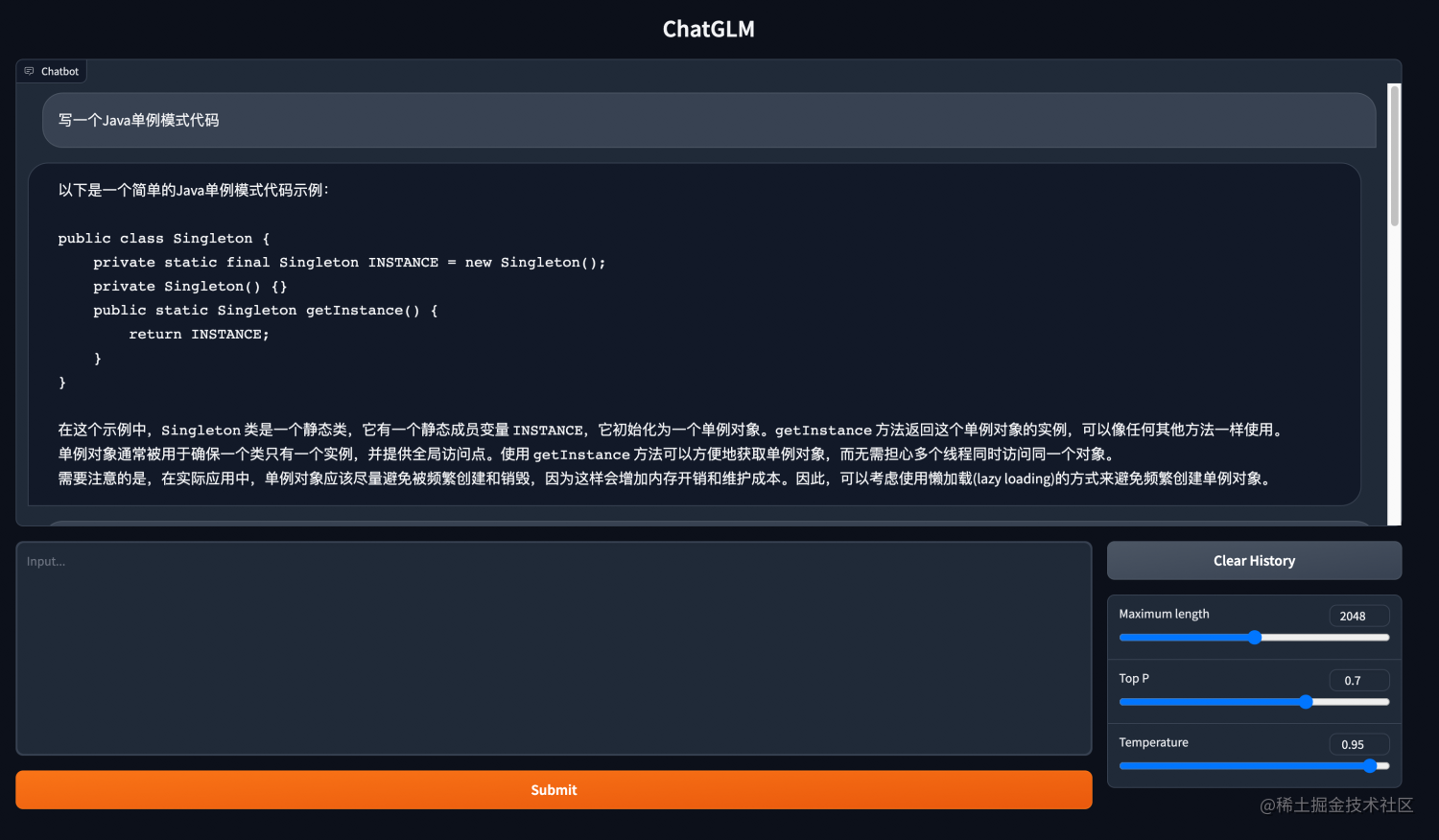
大家好,今天我们一同来探讨一下那些大模型背后的核心技术!Transformer模型,无疑是大型语言模型的坚实基石,它开启了深度学习领域的新纪元。在早期阶段,循环神经网络(RNN)曾是处理序列数据的核心手段。尽管RNN及其变体在某些任务中展现出了卓越的性能,但在面对长序列时,它们却常常陷入梯度消失和模型退化的困境,令人难以攻克。为了解决这一技术瓶颈,Transformer模型应运而生,它如同黎明中的