




- @kexin197
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了使用QClaw和skill-creator工具快速创建AI技能的流程。首先下载QClaw和skill-creator技能包,然后在QClaw中加载该技能。通过对话指令基于skill-creator创建一个名为"video-convert-doc"的新技能,实现将B站视频音频转为文本的功能。虽然CPU环境下8分钟音频需5-10分钟处理,但验证了该方法的可行性。这套方案展
文章摘要:本文介绍了一个基于《红楼梦》知识图谱的问答系统实现方案。通过Neo4j存储知识图谱数据,采用LangChain框架构建查询流程。系统设计了双层路由机制,结合关键词匹配和LLM判断问题类型(KG或RAG),并使用缓存优化查询性能。特别实现了KG+RAG混合模式,先通过知识图谱查询核心关系,再结合文档检索获取背景信息,提升回答质量。文中详细展示了Cypher查询生成、路由分类和缓存查询等核心
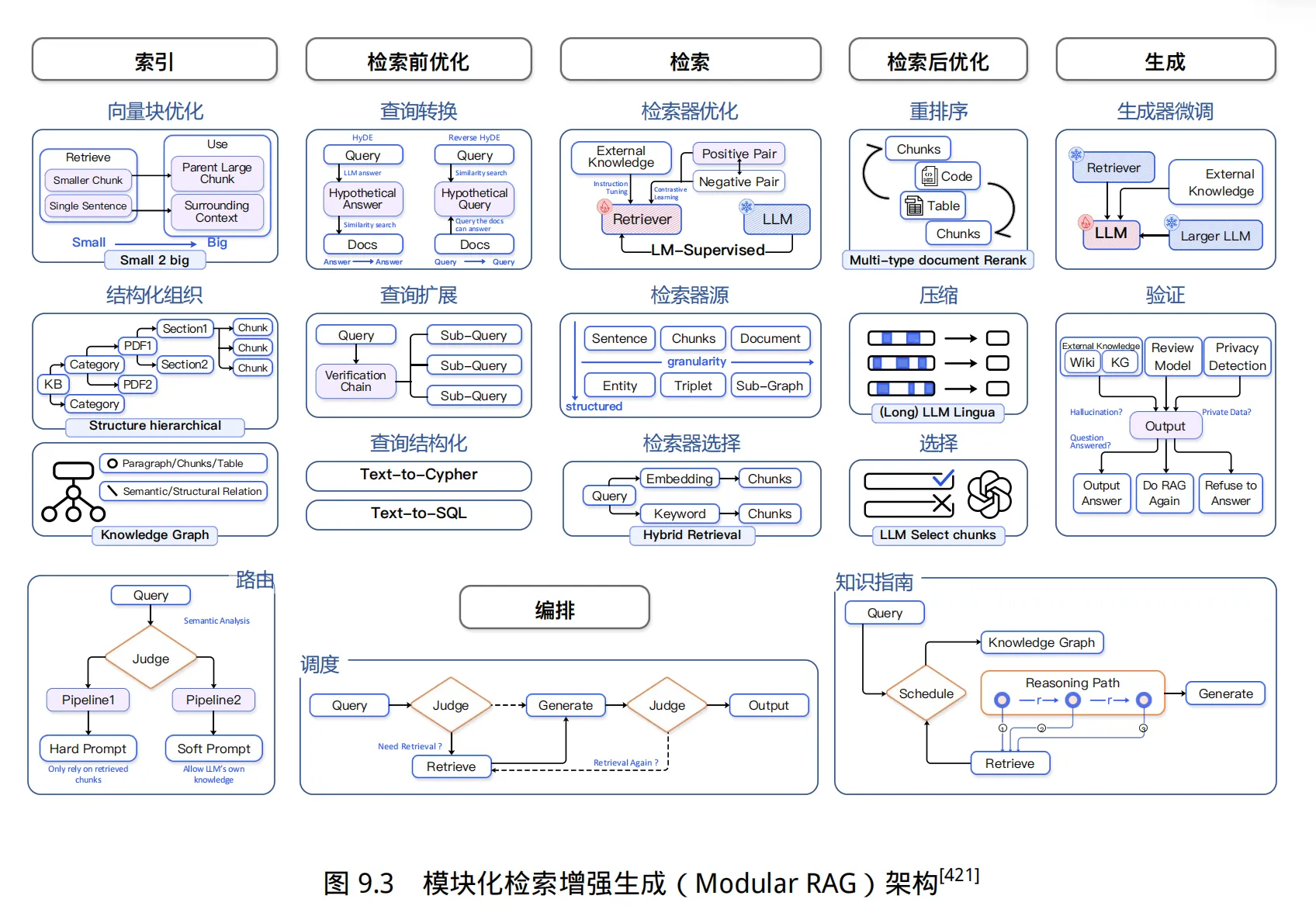
RAG(检索增强生成)技术通过结合检索和生成模块,显著提升大语言模型的性能。其核心优势包括生成内容更准确、知识即时更新、可解释性高、缓解幻觉问题,并保障本地数据隐私。RAG系统采用模块化架构,主要步骤涵盖索引构建、检索优化、生成及编排等环节。关键技术涉及文本嵌入模型微调、查询优化(如RQ-RAG算法)、幻觉感知生成模型(如RAG-HAT)、重排模型(如JudgeRank)以及检索生成联合优化(如R
本文系统介绍了分布式训练的核心概念和技术方法。首先阐述了分布式训练的基本原理和目标,即通过并行计算加速模型训练。重点分析了三种主要并行策略:数据并行、模型并行(包括流水线并行和张量并行)及混合并行,详细说明了各自的实现方式和优化技术(如1F1B调度、ZeRO优化器等)。同时探讨了参数服务器和去中心化两种主流架构设计及其通信机制,比较了同步/异步训练模式的特点。最后介绍了分布式集群中常用的集合通信原
本文系统介绍了分布式训练的核心概念和技术方法。首先阐述了分布式训练的基本原理和目标,即通过并行计算加速模型训练。重点分析了三种主要并行策略:数据并行、模型并行(包括流水线并行和张量并行)及混合并行,详细说明了各自的实现方式和优化技术(如1F1B调度、ZeRO优化器等)。同时探讨了参数服务器和去中心化两种主流架构设计及其通信机制,比较了同步/异步训练模式的特点。最后介绍了分布式集群中常用的集合通信原
本文系统介绍了混合精度训练(FP16+FP32)的技术原理与实现流程。该方法通过主权重(FP32)与计算权重(FP16)的协同工作,配合损失缩放(Loss Scaling)技术,有效解决了低精度训练中的数值稳定性问题。关键步骤包括:前向传播使用FP16加速计算,损失值保持FP32精度;反向传播时对梯度进行缩放处理,确保其在FP16可表示范围内;最终用FP32精度更新主权重。这种方案在提升计算速度(
本文主要探讨了大模型训练中的显存占用问题,重点分析了模型参数、优化器状态和激活值的存储需求。指出优化器需要额外存储参数状态(如Adam优化器每十亿参数需8-16GB显存),解释了为何某些中间值(如平滑值)不能使用float16存储以避免精度损失。文章详细计算了注意力机制中各张量的显存占用,特别强调了与序列长度平方相关的bs²a项,并提供了相关参考链接和视频资源。这些分析为大模型的显存规划提供了重要
本文系统梳理了强化学习的核心方法体系。主要内容包括:1)表格型方法的三种形式(状态价值、动作价值、最优动作)及其离散空间的局限性;2)环境模型的两要素(状态转移概率和奖励函数);3)有模型方法(动态规划、策略迭代、价值迭代)和无模型方法(蒙特卡洛、时序差分、SARSA、Q-learning)的算法原理;4)重点解析了策略迭代的价值评估与改进过程,以及价值迭代的最优方程逼近;5)详细介绍了ε-gre
打开你的命令行终端 (如 PowerShell 或 CMD),执行成功的话,命令行最前面应该有一个(unslothAmr)首先,创建一个独立的 Conda 环境以隔离项目依赖。请确保文件夹路径不包含中文字符,以避免潜在问题。装了一天终于装好了。试了包括CSDN自己的平台,看了好多帖子,没想到最后用很简单的方法就装好了。后,新建一个notebook,选择内核 "Python (unslothAmr)
本文介绍了三种大模型微调方法:全参数微调、LoRA和QLoRA。全参数微调调整所有参数,性能好但显存占用高;LoRA通过低秩分解冻结原参数,仅训练旁路低秩矩阵,显存需求大幅降低;QLoRA在LoRA基础上引入4bit量化技术,进一步减少显存占用。文章详细解释了LoRA的配置参数、QLoRA的NF4量化原理和双重量化技术,并介绍了分页优化器应对内存峰值的方法。三种方法各有优劣,全参数微调适合高性能需