




- @hml111
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文总结了生产环境中常见的大模型部署问题及解决方案。针对显存溢出(CUDA out of memory)问题,建议检查模型大小、调整KV Cache配置参数;多卡NCCL错误可通过检查GPU拓扑或临时禁用多卡通信解决;请求无响应问题可通过增大max-num-seqs等参数优化;PyTorch CUDA版本错误需重新安装GPU版本;模型加载卡顿可通过使用国内镜像或修改缓存权限解决。总体排查思路为:先

本文总结了生产环境中常见的大模型部署问题及解决方案。针对显存溢出(CUDA out of memory)问题,建议检查模型大小、调整KV Cache配置参数;多卡NCCL错误可通过检查GPU拓扑或临时禁用多卡通信解决;请求无响应问题可通过增大max-num-seqs等参数优化;PyTorch CUDA版本错误需重新安装GPU版本;模型加载卡顿可通过使用国内镜像或修改缓存权限解决。总体排查思路为:先
本文介绍了vLLM框架的性能调优策略,重点围绕显存管理、吞吐量和延迟三个核心目标展开。通过调整模型参数(如模型精度、显存利用率)、并发控制参数(批处理token数、最大序列数)以及延迟优化参数(交换空间、执行模式),实现不同场景下的性能优化。文章提供了三种典型场景的配置模板:高并发API服务侧重吞吐稳定性,实时对话追求低延迟,离线批量生成则最大化吞吐量。调优本质是在显存占用、并发能力和响应速度之间

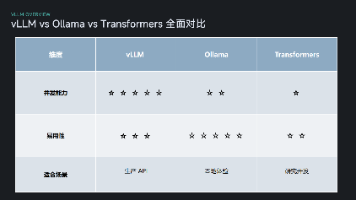
当你能把模型都跑起来后,下一个问题往往是:那我到底该选哪个方案长期使用?通常都知道Ollama 很方便,Transformers 很灵活,vLLM 很高性能,具体如何定夺还不是那么简单,还需要根据具体场景来选择,本文就对这三个框架深入对比研究,共各位开发伙伴参考。本文准备从性能、易用性、架构设计、适用场景等角度来分析,从而清楚三者差异,帮你在“能跑”和“能商用”之间做出理性选择。
本文详细介绍了在WSL2环境下安装vLLM大语言模型推理框架的完整流程。核心步骤包括:1)检查并配置WSL2环境,确保支持GPU透传;2)安装NVIDIA驱动和专用CUDA Toolkit(WSL-Ubuntu版本);3)配置Python虚拟环境并安装支持CUDA的PyTorch;4)最后通过pip安装vLLM核心库。整个过程强调必须使用GPU加速环境,并提供了各环节的验证方法,包括nvidia-
