- @hhue2007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI 不仅仅是一种工具,而是一个正在“黑进”并重塑人类文明操作系统(语言与数据)的主体Agent。未来在数据知识层面,AI将会成为主体,人类将成为“次子”地位,但在“生命体验”这一维度,人类依然是唯一的、不可替代的主体,我们要时刻保持这种对“身临其境感受”的坚守,这将会是未来社会最高级阶层所拥有的核心竞争力,大家要在自己的人生道路中不断坚守这一底线,不用在AI擅长的领域与其竞争。
人工智能正从辅助工具转变为业务核心引擎,通过“乘数效应”实现生产力跃升。AIAgent作为智能化落地的关键,需突破“最后一公里”的体验与成本矛盾,聚焦代理体验(AX)、结构化理解、可预测决策框架及四大战略机遇(AI原生内容、工具市场、监测平台、协作协议)。未来竞争将围绕Agent信任体系展开,需构建人机协作、伦理规范与新职业生态,实现从“争夺注意力”到“赢得AI信任”的范式转变,推动智能化普惠。

本文系统梳理了AI智能体(AIAgent)相关核心概念与技术要点。主要内容包括:1)常见问题解析,涵盖提示链、路由模式、知识检索(RAG)、多智能体协作等10个关键问题;2)核心术语词汇表,详细定义20个专业术语,如智能体系统、并行化、反思模式等。文章重点分析了AI智能体的工作原理、技术实现及其局限性,特别强调了提示工程、记忆管理和推理能力等关键技术。这些内容为理解当前AI智能体的技术架构和应用场
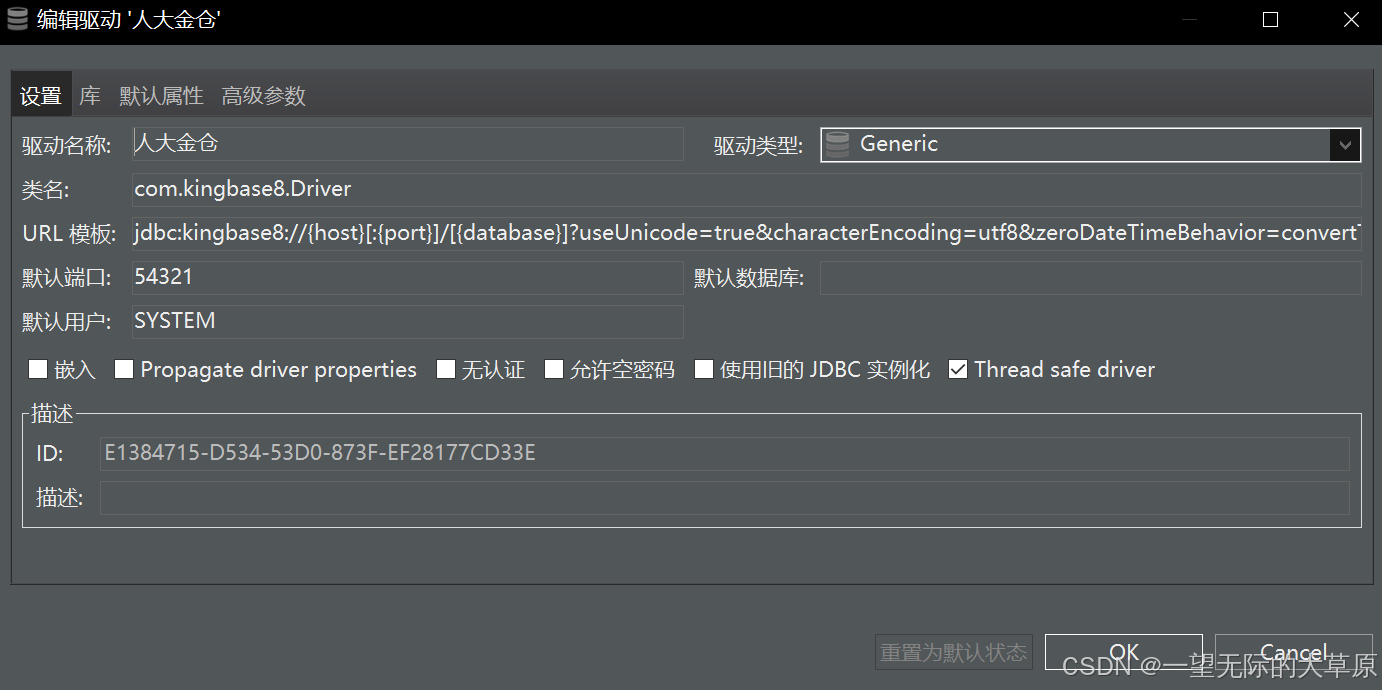
我们已经习惯使用DBeaver连接各种成熟的商业或开源数据库,想着如何继续基于该工具,连接MongoDB和人大金仓数据库,查了半天很多地方说法不统一,所以自己就简单整理了一个如何利用DBeaver成功配置并连接这两类数据库,主要是配置信息如何编写,驱动库如何配置等。
MS SQL Server2017无法按照python和R环境的问题解决办法。
介绍了两种在飞书群聊中实现多Agent协作的免@响应方案。方案一通过修改.env配置文件和feishu.py代码,指定特定群组免@响应;方案二进一步扩展功能,允许为不同群组设置差异化响应规则(免@/需@/完全禁用)。两种方案均需调整环境变量和Python代码,其中关键修改包括添加FEISHU_FREE_RESPONSE_CHATS参数、调整群组规则配置逻辑等。完整实现代码已开源在GitHub库中,
《设计原本》中探讨设计的本质,认为卓越设计源于概念完整性而非流程。核心观点包括:1)设计是发现需求而非执行流程;2)迭代探索优于瀑布模型;3)约束是创新的催化剂;4)团队协作应聚焦统一设计概念;5)AI时代人类设计师的核心价值在于定义问题与建立概念模型。全书强调设计是构想-实现-交互三阶段中的构想阶段,其根本在于心智过程而非技术实现,这一本质在AI时代更显珍贵。设计从来不是寻找答案,而是发现问题。
主要介绍了在Obsidian中接入Gemini3大模型服务的两种插件方案。首先需要注册Google AI Studio账号获取API Key,然后在Obsidian中安装CopilotPlus和GeminiScribe插件。CopilotPlus通过设置API Key并添加模型列表实现接入,GeminiScribe则需配置API Key后自动设置各类模型。两种插件都能在Obsidian侧边栏生成交
探讨AI时代下知识工作者的生存策略。作者达文波特提出核心范式应从自动化转向智能增强,强调人机协作而非竞争。书中揭示AI正通过沉默解雇侵蚀职业基础,并给出五大应对策略:管理者需全局掌控(超越)、创意者发挥非认知优势(避让)、跨界人才连接技术与业务(参与)、专家深耕利基领域(专精)、技术者开发新系统(开创)。全书主张将AI作为头脑的自行车来拓展人类能力边界,在可编码任务被接管后,通过发挥人类特有的创造
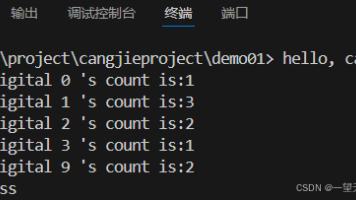
利用仓颉编程语言实现如何统计一个正整数中各个数字出现的次数的小应用。目前看仓颉可供参考的资料还是偏少,只能看官方的开发指南或sdk,详见华为官方文档,目前用各类搜索引擎或者deepseek等大模型搜索,回复基本都将其认为是一种输入法,查找内容都不理想。因此,本次就参考官网sdk进行了实现,其实实现原理很简单,如果用python、java等语言实现非常容易,整体思路就是采用除法取余方式计算每一位的