- @haveqing
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenAI将Codex集成到ChatGPT桌面端,用户需先配置网络代理并创建账号。安装通过微软应用商店完成,若已登录则直接显示用户信息。首页提供"开始使用"指引和创建项目功能。相关资源包括OpenAI官方链接和Windows版安装程序ChatGPTInstaller.exe。该整合强化了AI编程辅助能力,简化了开发环境搭建流程。
本文详细介绍了如何通过Hermes工具配置本地Ollama模型服务的步骤。主要内容包括:1) 使用hermesmodel命令选择自定义端点并配置Ollama服务地址;2) 设置API兼容模式为Chat Completions;3) 从可用模型列表中选择所需模型;4) 通过hermesconfig命令查看和修改配置参数(如上下文长度262144);5) 配置文件保存位置及命令行配置方法。最终实现在H
本文记录了在Win11 WSL2 Ubuntu24.04环境下配置OpenViking服务的完整过程。主要内容包括:1)备份数据并切换至本地VLM模型Qwen3.6 35B;2)将嵌入模型从OpenAI切换为本地Qwen3-Embedding 0.6B;3)处理向量数据重建时的配置调整,包括添加allow_metadata_override参数;4)优化Ollama配置提升处理性能;5)执行资源库
journalctl --user -u hermes-gateway -f (这个不全,别用)”企业,用于测试,无需企业认证,有工作台,可以管理企业,可以创建管理智能机器人。个人组件团队,太简单了,没有工作台,不好管理企业,不好(创建)管理智能机器人。安全与管理--管理工具,选择智能机器人,管理,选择智能机器人,点编辑。聊天成功后,可以发/whoami,返回User ID。可以先空着,不填的话,
本文提供了Docker在Windows系统上的详细安装指南。主要包括:1)相关官方文档链接;2)安装步骤详解,包括注意事项(如不勾选Windows Containers选项)和自动安装的Windows功能;3)安装验证方法(docker --version命令);4)关键目录和文件位置说明(如Docker安装目录、WSL虚拟硬盘文件路径等);5)Docker Engine配置文件和WSL文件资源访
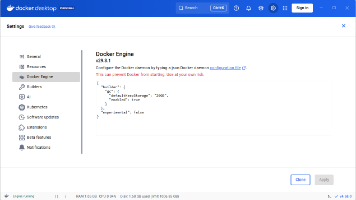
本文介绍了配置Docker镜像加速器的三种方法。第一种是通过阿里云获取个人专属镜像地址;第二种推荐在Docker设置界面直接修改JSON配置,添加阿里云、网易和百度镜像源;第三种是修改系统配置文件,针对不同操作系统(Windows、Linux、macOS)分别说明了配置文件的存放位置和修改方式。所有方法最终都需要在配置中添加相同的镜像源地址。
本文介绍了Jupyter Notebook虚拟内核的安装与卸载方法。安装时使用python -m ipykernel install命令,可指定--user参数避免权限问题,并通过--name和--display-name设置内核名称和显示名称。卸载时使用jupyter kernelspec uninstall命令,支持批量删除多个内核。文中还展示了具体操作示例,包括列出已有内核、安装多个新内核(
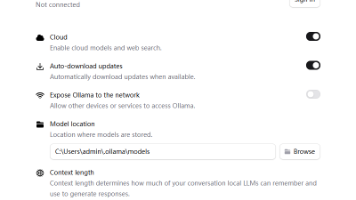
可以把这个写入到:~/.bashrc,然后:source ~/.bashrc。默认模型存储位置:~/.ollama/models。如搜索:deepseek,Qwen,gemma。可能会卡,稍后再试,或者打开网络代理。包括:将Ollama添加为启动服务。--verbose 显示统计信息。每次回复后都会显示统计。最新版本0.20.7。Ollama中文文档。
建议在WSL2的Ubuntu中安装vLLM以避免Windows兼容性问题。安装方法:通过阿里云镜像pip install vllm,验证版本后即可使用。主要命令vllm serve支持加载HuggingFace模型或本地路径,可配置张量并行(多GPU)、上下文长度(如32K tokens)和量化选项(如GPTQ-int4)。典型用例包括:32B大模型需2个GPU并行,7B小模型单GPU运行。关键参
Ollama使用指南摘要 Ollama是一个本地运行大语言模型的工具,支持多种AI模型的下载和管理。主要功能包括:1)通过官网下载安装包或使用PowerShell脚本安装;2)支持搜索和下载不同参数的模型(如deepseek-r1);3)提供命令行交互界面,可查看本地模型列表、运行状态及统计信息;4)允许自定义模型存储位置;5)包含丰富的命令集(pull/run/stop/list等)。典型使用流