- @frxnance
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
看下Deepseek怎么说?AI 领域的评测是指通过系统化的方法和工具对人工智能技术的性能,可靠性,适用性及伦理性进行全面评估的过程,其核心目标是验证AI 在不同场景下的实际效果,确保其技术价值与社会需求相匹配。感觉其实就是回到开篇所说的,评测其实涉及了多个方面:技术性能,硬件评测,应用场景评测,伦理与安全评测等。

每个词都能关注句子中的其他词,从而理解句子的含义数学不好,Transformer 里面涉及复杂的数学知识有点令人费解,它的主要流程是:输入处理阶段需要分词、嵌入、位置编码。编码器部分需要自注意力和前馈网络,解码器部分需要掩码注意力和交叉注意力。输出生成需要线性层和softmax。让deepseesk 通俗讲解一下:

关键行动项每日:执行核心支付对账测试(5分钟级)每周:红蓝对抗演练(覆盖3种攻击向量)每月:全链路混沌工程测试(破坏性场景验证)当某次大促的每秒万笔交易洪峰平稳度过时,背后是测试工程师在黑暗中模拟过217次数据库崩溃和56种优惠漏洞攻击。资损防控没有银弹,但有永不松懈的测试守卫者。
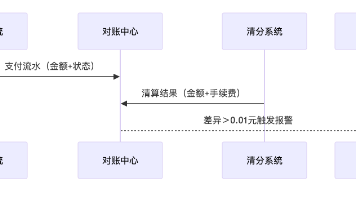
某金融平台微服务重构后,因支付服务接口字段变更未同步通知,导致对账服务凌晨崩溃,损失。。
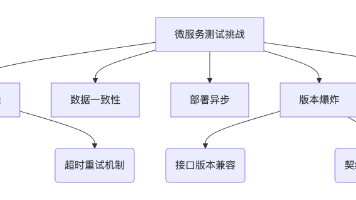
传统错误:HTTP 5xx、超时、数据校验失败AI特有错误认知错误:错误理解用户意图生成错误:事实性矛盾/逻辑错误记忆错误:关键信息遗忘或错乱腾讯TMF监控实践在元宝系统中,业务错误码分层定义"5001": "语义理解错误","5002": "知识检索失败","5003": "推理过程异常","5004": "记忆存储冲突"
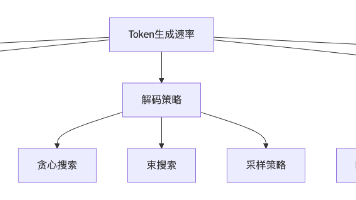
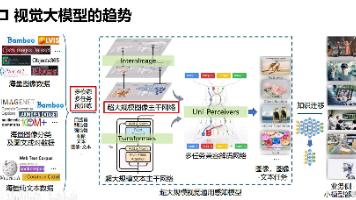
学习路线大模型演进路线:视觉大模型趋势特征基于前置任务学习基于对比学习基于掩码重建学习核心驱动人为设计的代理任务区分正负样本对根据上下文重建被掩码的数据主要目标解决特定代理任务拉近正样本,推远负样本最小化重建误差关键操作预测伪标签计算对比损失 (InfoNCE 等)掩码输入,预测被掩部分信息利用任务定义所需的信息样本间(对)的相似/不相似关系数据内部的上下文依赖关系优点设计灵活,直观表示判别性强,
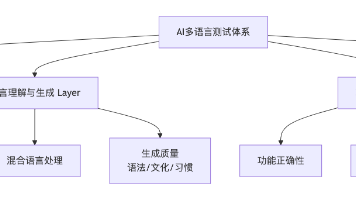
在全球化市场中,AI应用的多语言能力(Multi-language)和本地化(Localization)质量直接决定了其用户体验和市场天花板。测试像“腾讯元宝”这类大型语言模型(LLM)应用,远不止简单的界面翻译验证,它是一项涵盖的复杂系统工程。本文将系统性地阐述一套可落地的测试方案。
本来以为是一本偏软技能的普通书籍,同事推荐的书,感觉可以看下,另外还有一本是《卓有成效的管理者》,最近看短视频看到个观点,当你看一本书的时候,如果当时你对它的感触不够深,但是后面当你重新翻看的时候,你会惊喜发现为什么当初都没有注意到书中的观点是那么精辟一针见血。其实是因为你当时自我所处的现状和书中的内容无法匹配,所以无法深入去理解到书中作者站的位置去读懂作者想要表达的意思。所以对于这两本书,我选择

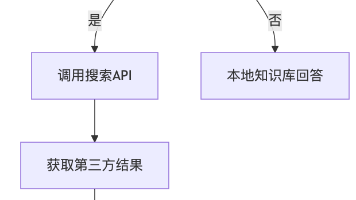
我会分三层验证前端交互层:测试触发条件、结果展示规范性;服务集成层:通过Mock验证API容错,压测多链路稳定性;内容安全层:检查来源标注、内容过滤、隐私合规性。创新点:引入污染数据测试和时效性验证,确保搜索功能既精准又安全。此方案可直接应用于实际工作场景,建议补充LangChain的Agent测试工具或自定义评估数据集以提升竞争力。是否需要进一步拆解某部分细节?