




- @fkyyly
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
claude code
转自http://blog.csdn.net/stan1989/article/details/8565499
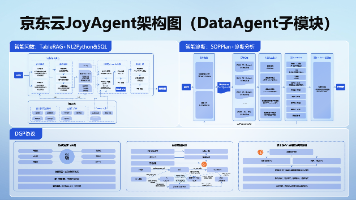
JoyAgent,Dataagent,数据分析,归因分析,羚羊
claude code
https://github.com/BshoterJ/awesome-kgqa
目录(一)Few-shot learning(少样本学习)1. 问题定义2. 解决方法2.1 数据增强和正则化2.2 Meta-learning(元学习)(二)Meta-learning(元学习)1. 学习微调 (Learning to Fine-Tune)2. 基于 RNN 的记忆 (RNN Memory Based)3.度量学习 (Metric Learning)4.方法简单比较5.未来方向5
JoyAgent,Dataagent,数据分析,归因分析,羚羊
目录(一)Few-shot learning(少样本学习)1. 问题定义2. 解决方法2.1 数据增强和正则化2.2 Meta-learning(元学习)(二)Meta-learning(元学习)1. 学习微调 (Learning to Fine-Tune)2. 基于 RNN 的记忆 (RNN Memory Based)3.度量学习 (Metric Learning)4.方法简单比较5.未来方向5
错误:Importing the multiarray numpy extension module failed原因:环境变量的问题其中Pycharm虚拟环境变量引用了系统环境变量,而系统环境变量起初并没有引入C:\ProgramData\Anaconda3\Library\bin所以才导致了Pycharm虚拟环境导入numpy失败,原因就在于包混乱,所以在系统环境变量中导入,也一定要导入到bi
导读】知识图谱一直是学术界和工业界关注的焦点。最近Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, Philip S. Yu等学者发表了关于知识图谱的最新综述论文《A Survey on Knowledge Graphs: Representation, Acquisition and Applications》,25页pdf涵盖10