




- @evilstar2015
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
项目代码解析
Codex订阅费用高涨可能与自动加载的上下文内容有关。新会话会默认加载项目指导文件(AGENTS.md)、配置解析结果、启用的Memories、Skills初始清单、插件/MCP能力定义和工作环境信息。其中Skills和插件即使未使用也会占用token,Memories若开启也会跨会话共享信息。 要节省token可采取以下措施: 精简或删除不必要的AGENTS.md文件 关闭Memories功能

Dify 支持 40+ 主流大语言模型提供商,通过统一的模型运行时层(Model Runtime)实现了对不同 LLM 服务的抽象和封装。这种设计使得开发者可以轻松切换不同的模型提供商,而无需修改应用代码。

v0.17.0 的主题是扩大 Hermes 的运行边界。它新增 iMessage Photon、Raft gateway channel、官方 WhatsApp Business Cloud API、Telegram rich message、后台子 Agent、图片编辑、自动化蓝图、Dashboard profile builder、Skills Hub 重构、Memory 批量操作、桌面端多项

日期范围: 2026-03-25 - 2026-03-31摘要: 2026.3.28 大版本发布(71 贡献者),xAI x_search 集成、插件审批钩子、ACP 通道绑定为亮点;用户体验灾难汇报引热议;Windows Defender 误报安装脚本;Shoofly/Snyk 发现 36% ClawHub 技能存在安全缺陷;Feishu/微信插件路径回归持续发酵。

本周最大爆点是 Anthropic 宣布 Claude 订阅不再覆盖 OpenClaw 等第三方工具(HN 1090分),同时曝出 CVE-2026-33579 权限提升漏洞(HN 513分)。发布节奏空前密集:单周 4 个 stable + 1 个 beta(2026.4.1/4.2/4.5 + 4.6-beta),2026.4.5 引入 video_generate/music_generat

本周AI Agent Skills生态发展呈现以下特点:官方仓库更新放缓,生态增量主要来自第三方高星Skill和垂直场景工具化。重点包括: 核心仓库:anthropics/skills仍是生态锚点,但治理压力大;ComposioHQ/awesome-claude-skills维持高流量,但提交频率低。 热门Skill: 设计生产力:nexu-io/open-design(59.6k stars)整

Dify支持28+向量数据库集成,为RAG应用提供多样化选择。系统涵盖开源方案(Milvus、Qdrant等)、云服务(阿里云AnalyticDB、腾讯云VectorDB等)和专用数据库(TiDB Vector等),通过统一接口实现向量操作。架构设计包含Vector Factory层管理连接,提供核心功能如创建集合、添加文本、向量搜索等。支持环境变量配置不同数据库参数,开发者可根据需求灵活选择最优

v0.17.0 的主题是扩大 Hermes 的运行边界。它新增 iMessage Photon、Raft gateway channel、官方 WhatsApp Business Cloud API、Telegram rich message、后台子 Agent、图片编辑、自动化蓝图、Dashboard profile builder、Skills Hub 重构、Memory 批量操作、桌面端多项
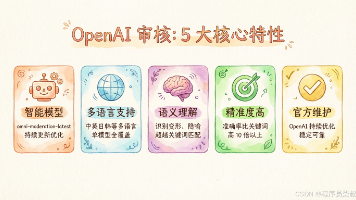
摘要: OpenAI 审核是 Dify 内置的智能内容审核方案,基于 OpenAI Moderation API 实现高精度合规检查。该功能支持多语言语义理解,可配置输入/输出审核,通过预设响应处理违规内容。核心实现包括数据结构验证、OpenAI API 调用逻辑及配置管理,支持 UI 和 API 两种配置方式。使用时需确保 OpenAI API Key 有效,并至少启用输入或输出审核之一。
用户反映 Claude Code 在检测到 commit 信息中包含"OpenClaw"时会拒绝执行请求,甚至有报告称触发额外收费。这一事件在 HN 引发激烈讨论,被视为 Anthropic 平台博弈进入新阶段——上周(W18)刚达成"允许 OpenClaw CLI 使用"的和解,本周又出现新的摩擦点。718 条评论中充斥着对 AI 厂商平台控制权的担忧。
