- @devnullcoffee
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 本文为一篇面向中高级开发者的深度技术实践指南,旨在详细阐述如何设计并实现一个高可用、可扩展的亚马逊竞品Listing监控系统。文章内容将覆盖:1)应对亚马逊反爬策略的采集层设计;2)基于微服务架构的系统解耦与任务调度;3)使用Python和第三方Scrape API进行 #亚马逊Listing数据采集 的完整代码示例;4)集成AI/ML模型进行高级数据分析与预测的技术探讨。1. 系统设计的
摘要: OpenClaw AI Agent 若未接入实时数据 API,仅相当于套壳 ChatGPT,无法提供准确的电商运营决策。本文指出 LLM 本质是逻辑引擎而非实时数据库,无法获取亚马逊实时数据(如 BSR 排名、竞品价格等),并分析了自建数据采集的技术难点(动态渲染、反检测、解析维护)。推荐通过 Pangolinfo Scrape API 实现高效接入,提供完整代码方案,支持自动获取商品数据

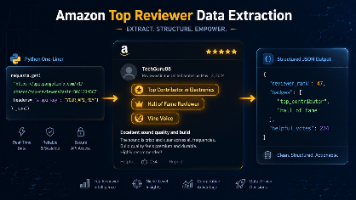
摘要 本文解析Amazon Top Reviewer数据采集的技术挑战与解决方案。Amazon评论者权威体系包含5个等级,其中Hall of Fame评论者的影响力是普通用户的31倍。传统爬虫面临三大技术障碍:排行榜页面下线、动态懒加载机制和登录墙限制。对比三种技术方案:静态爬虫完全失效,Playwright方案维护成本高且不稳定,而Pangolinfo API提供结构化数据接口,可直接获取包含r
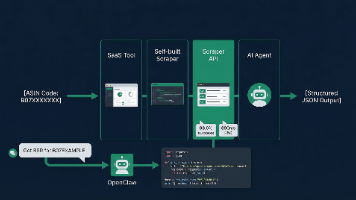
亚马逊ASIN数据采集方案技术对比 本文分析了四种亚马逊ASIN商品详情数据采集方案: SaaS工具(如卖家精灵):适合小规模人工查询,但存在更新频率低、字段受限等问题,不适合大规模自动化采集。 自建爬虫:完全自定义但维护成本高,需持续对抗亚马逊的反爬系统(IP封锁、设备指纹等),月均维护时间40-60小时。 Scraper API:目前主流商业方案,提供稳定生产级数据管道。实测采集成功率达98.
本文系统讲解了如何构建具有竞争壁垒的亚马逊AI选品分析系统,提出当前工具仅解决效率问题,而真正的核心在于语义理解+自定义分析框架。文章详细介绍了三个关键技术组件:评论语义分析系统(包含数据采集、预处理、LLM分析全流程)、竞争位置数据采集和AI Agent工作流设计,并提供了完整的Python代码实现示例。通过语义分析评论文本、挖掘用户痛点和差异化机会,这套方法能够突破传统选品工具的数据陷阱,获取
在数据分析的汪洋中,真正拉开技术团队差距的,不仅是数据获取的速度,更是数据合规的厚度。在大数据的时代洪流中,真正拉开跨境企业差距的,不仅是获取公开数据的技术速度,更是深谙合规边界、将海量信息转化为敏捷决策的商业智慧。
摘要(149字): 亚马逊2026年将AI购物助手Rufus整合进Alexa for Shopping,重构了搜索页面结构,新增AI摘要、推荐商品和Prompts广告三大模块。本文解析其技术架构,指出自建爬虫面临动态渲染、反爬系统和DOM频繁变更等挑战,推荐使用Pangolinfo Alexa API解决方案。该API提供住宅代理轮换、指纹伪装和实时解析服务,并附Python代码示例,展示如何通过
在亚马逊上,一件服装可能有颜色 × 尺码的 30 个子 ASIN,一个耳机可能有颜色 × 版本 × 认证区域的 48 个子 ASIN。如果你需要监控竞品的全量变体价格,实际需要处理的数据量是「商品数量」的 15–25 倍。亚马逊的反爬机制让这件事进一步复杂:IP 频率限制、动态 JS 渲染、地理封锁,每一项都会降低自建爬虫的成功率。本文从技术原理到工程实践,给出一套完整的解决方案。
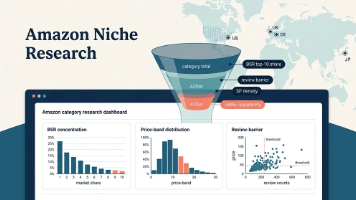
亚马逊类目选品数据分析实战摘要 本文介绍了一个基于Python和Scrape API的六维决策框架,用于亚马逊类目选品分析。框架包含6个关键指标:BSR集中度(衡量头部卖家垄断程度)、评论壁垒(分析进入门槛)、新品速度(反映市场活力)、价格带覆盖(评估竞争空间)、SP广告位密度(判断推广难度)和差评聚类(发现产品痛点)。通过Pangolinfo Scrape API获取类目数据,相比通用爬虫具有更
在跨境电商工具赛道,基于大模型构建“AI 选品 Agent”已经成为标配。然而,无数开发者在落地时遇到了一个致命的业务痛点:Agent 输出的选品报告缺乏商业指导价值,经常用过期的滞后指标(如月更的静态库数据)给出看似合理、实则导致卖家面临高额 PPC 成本和滞销风险的“死亡建议”。本文将从技术架构与真实案例的角度,深度解析为什么脱离实时数据采集的 Agent 无法应对高时效性的亚马逊选品场景,以