




- @cxx654
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近在学习郑泽宇老师的《Tensorflow实战Google深度学习框架》,书中样例代码写的非常简洁、易懂,而且逻辑性很强,在这里进行记录一下。 以下样例代码使用tensorflow框架构建两层全连接神经网络,识别MNIST手写数字数据集。其中用到了一些优化方法:使用滑动平均模型控制权值参数的变化率、定义学习率的衰减率控制学习率的变化率,使得在模型训练初期,模型参数变..
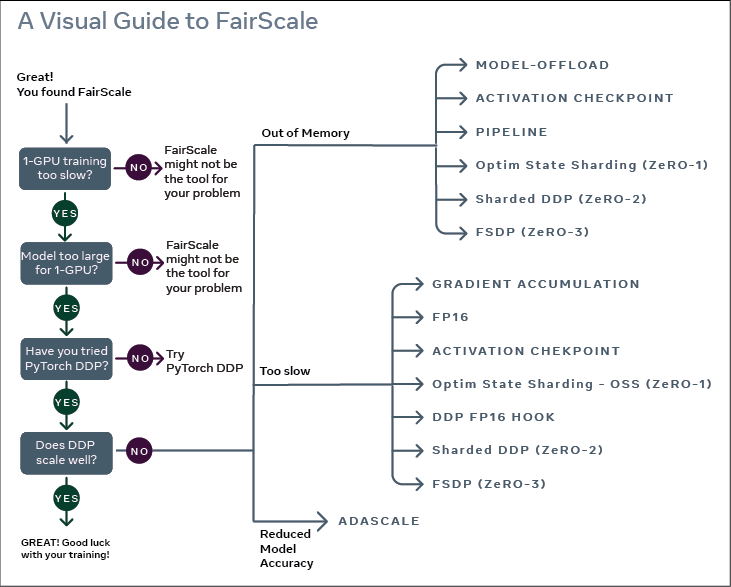
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed(环境没搞起来)模型训练代码,并对比不同方法的训练速度以及GPU内存的使用
如何识别未在训练集中没有出现过的类别

Torch.onnx.export执行流程:1、如果输入到torch.onnx.export的模型是nn.Module类型,则默认会将模型使用torch.jit.trace转换为ScriptModule2、使用args参数和torch.jit.trace将模型转换为ScriptModule,torch.jit.trace不能处理模型中的循环和if语句3、如果模型中存在循环或者if语句,在执行tor

人脸识别服务需要包括以下几个功能模块:1、人脸检测和人脸校正模块2、人脸特征提取模块3、人脸特征匹配模块4、人脸识别结果计算模块这篇文章简要介绍一下人脸特征提取部分。上一篇文章中简要介绍了一下人脸识别的过程,这篇文章较少一下人脸特征提取部分。人脸特征人脸特征提取:人脸特征提取的目的就是将人脸图像进行向量化表示,因为程序代码是没办法直接处理图像数据的,必须要将其数字化,提到向量就自然而然的会想到向量
人脸识别服务需要包括以下几个功能模块:1、人脸检测和人脸校正模块2、人脸特征提取模块3、人脸特征匹配模块4、人脸识别结果计算模块这篇文章简要介绍一下人脸检测和人脸校正部分。人脸检测人脸检测:人脸检测顾名思义就是要准确检测出图像或者视频中的人脸区域位置。我个人常用的人脸检测方法包括MTCNN和RetinaFace,人脸检测的结果包括人脸区域在图像中的位置[x, y, w, h],x和y 表示人脸区域
示例excel文件内容:读取上述excel文件:# coding:utf-8import xlrdfrom xlrd import xldate_as_tupleimport xlwtimport osfrom datetime import datetimecurrent_path = os.path.dirname(os.path.abspath(__...
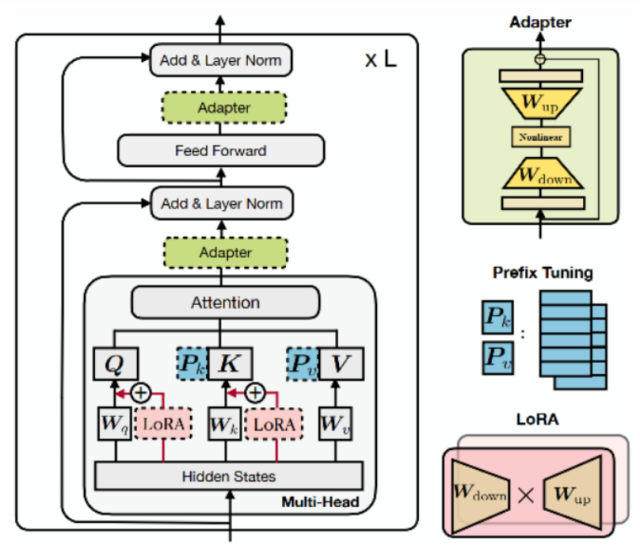
对于Auto-Encoding类型的任务,在模型的训练和预测阶段,self-attention都可以并行计算。在hugging face实现的self-attention模块中,为了复用decode生成阶段的key和value,会传入一个past_key_values参数,如果past_key_values不是None,表示前面时间步已经有计算结果了,直接复用上一步的结果,然后将当前时间步的key
如何识别未在训练集中没有出现过的类别