




- @comli_cn
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
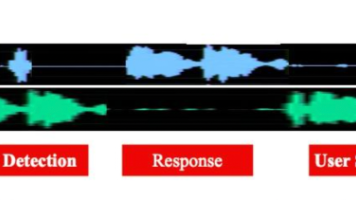
实现语音对话系统(SDS)中的全双工通信,需要在听、说、思考之间进行实时协调。本文提出了一种语义语音活动检测(VAD)模块,作为对话管理器(DM),以高效管理全双工SDS中的轮次切换。该语义VAD模块是一个轻量级(5亿参数)的大语言模型(LLM),在全双工对话数据上进行微调,能够预测四种控制标记以调节轮次切换和保持状态,区分有意和无意的插话,同时检测查询完成,以处理用户的暂停和犹豫。通过在短时间间
全双工语音对话是指系统具备在接收用户语音的同时生成语音输出的能力。这种设计将电信领域的“全双工”概念——即双向、同时通信——扩展应用于对话式人工智能,消除了人工设定的轮流对话限制,支持更自然的对话形式,如语音重叠、插话和中断。一个全双工对话模型的关键特性包括:同时听与说:模型在并行通道中实时处理输入并生成输出。灵活的轮流发言机制:系统能够处理用户的“打断发言”、提供及时的回应反馈(如“嗯”、“我懂
对下图所示的坐标图进行0和1的分类,如果用线性的分类器进行分类的话我们发现无法用一根线将0和1分开。上图中的绿色圈表示“或”运算,紫色圈表示“与非”运算,因为这两种运算都可以通过单层感知机实现,最后深蓝色的圈表示“与”运算,也是可以通过单层感知机实现的。通过这一系列的运算我们便实现了异或运算。...
参考.参考.
这里我用一个实例来实现以下BP神经网络计算的过程:这个实例中输入x1=1x_1=1x1=1,x2=−1x_2=-1x2=−1,输出y=0.5y=0.5y=0.5,w1w_1w1到w6w_6w6为参数。先通过上述模型计算出各个神经元的输入与输出:构造损失函数,这里我们使用交叉熵损失函数C=−y^lnyC=-\hat ylnyC=−y^lny接下来用反向传播来求解偏导数:到这一...
简单来说异常检测就是在一大堆数据中将正常的数据和异常的数据分开,把异常数据检测出来。具体方法就是通过训练集训练出一个可以用来做分类的函数。在进行异常检测的时候所提供的训练集有下面几种类型:1、训练集里面的样本都有标记,如果在测试集里根据分类函数分出来的某个样本不属于训练集里的任何一个类别则判定该样本为未知;2、训练集里所有样本均为正常样本;3、训练集里存在少许异常样本,但大多数均为正常样本,...
ERROR: Could not install packages due to an OSError: [Errno 28] No space left on device
1.深度学习中张量的作用深度学习中张量主要是为了便于用数字来描述一个对象,比方说要描述一张彩色图片,我们可以用(长,宽,颜色)来描述,所以描述一张彩色图片就需要用到三维张量,如果我们要描述一个彩色图片的集合那么就要就需要用(图片序号,长,宽,颜色)来描述,所以描述一个彩色图片的集合就需要用到四维张量。2.深度学习中张量的表达形式0维张量:[1]0维张量就是一个标量,说白了就是一个数字。...
主要有两个作用,一是省钱,二是减少耗时。目前通过api请求chatgpt等能力比较强的商业化大模型是要按token收费的,而且一点儿也不便宜。另一方面,大模型生成结果的速度比较慢,如果调用大模型做第三方应用的话很影响用户体验。如果可以对问题和大模型给出的对应结果做cache,下次再问到相同或者相似的问题时就可以直接查cache词典给出结果了,这样既省钱还能减少耗时。GPTCache就提供了这样的能
参考.参考.