




- @colorknight
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这个技术能够将使用者输入的通过自然语言描述的问题转换为可以回答问题的SQL语句,通过执行SQL语句返回数据结果并回答使用者的问题。在模板的json输出格式中我们看到,模板还要求LLM给出SQL语句的列说明,这也是因为从数据库中检索出的数据如果没有输出列说明,LLM在最后进行问题总结时是无法知道列的含义的。流程中除了之前我们描述的获取数据库Schema,通过Prompt模板拼接Prompt、调用De

SPSS、RapidMiner、KNIME以及Kettle四款工具都可以用来进行数据分析,只是彼此有各自的侧重点和有劣势。它们都可以逐步的定义数据分析过程,也同样都可以对数据进行ETL处理。笔者从自己关心的角度简单对比以上四款数据分析工具。 SPSS不用多说,一款成功的商业数据分析软件,涵盖了统计分析、数据挖掘分析等各种数据分析方法。界面简单易用,分析过程定义时非常直观方便。因为,
《企业级智能体的本体论转向:从工具自由到能力治理》摘要: 随着智能体从实验工具升级为企业核心系统,其是否需要本体(Ontology)引发行业分歧。研究表明,单体智能体通过上下文管理、工具调用等技术组合即可高效运作,但企业级部署需要根本性变革。本文提出"能力本体"新范式,将传统数据建模扩展为"数据语义+执行能力+运行方式"的统一治理层。在这种架构中,智能体退化
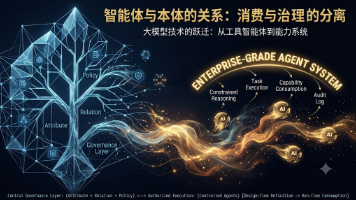
本文探讨了本体论在当代技术领域的复兴及其理论重构。文章指出,本体概念正被知识图谱、数字孪生、大模型等多个技术领域重新重视,但各领域对本体的抽象层级理解存在差异。传统本体模型主要描述静态结构(实体、属性、关系),却无法统一表达动态运行机制,导致结构与运行的断裂。 作者提出三位一体的本体重构方案:1)保留静态结构描述;2)引入"动作"作为能力表达单元,支持能力的组合与复用;3)通过

AI编程实践观察:效率与局限并存 大模型在编码执行层面已展现强大能力,可显著减少对人力的依赖。实践案例显示,AI能在2小时内完成原本需要3-4天的人工编码工作,尤其在语法解析等具体任务上表现惊艳。然而,其作为概率模型的本质导致输出不稳定——相同任务在不同上下文条件下可能产生截然不同的结果。当前AI更接近"高效问题求解器"而非"稳定生产系统",在工程层调试、架

本文探讨了动态本体的落地路径,指出Palantir通过Foundry系统实现了数据静态属性与动态行为的分离,但其高度工程化的方案存在开发门槛高、调试困难等问题。文章提出算子化与AI驱动是未来方向,并介绍了HuggingFists低代码算子协同平台如何通过"全栈算子"理念,实现逻辑与算力解耦、跨框架兼容和可视化编排,为动态本体提供标准化解决方案。最后强调动态本体需要平衡抽象能力与

本文详细介绍了OCR(光学字符识别)的工作流程。首先通过轮廓裁剪和透视矫正处理文本框内容,将倾斜文本拉正以提高识别准确率。然后进行文字识别,包括统一图片尺寸、转换为张量格式,通过模型输出字符概率分布。接着通过CTC解码将概率序列转换为文字,包括去重、去空白符和字典映射等步骤。最后指出工业级OCR还需解决场景适配、多语言支持、图像质量处理等问题,强调实际应用中细节优化的重要性。整个流程展现了OCR从
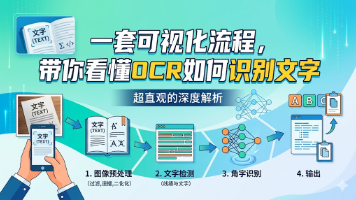
OCR技术通过两步流程将图片文字转换为可读文本:首先使用文本检测模型生成概率热力图,标识可能的文字区域;然后通过阈值处理、轮廓检测和优化等步骤,将模糊概率图转化为精确的文本框。整个过程并非单一AI模型完成,而是由检测和识别两个模型协同工作,先定位文字位置再进行内容识别。这种可视化流程揭示了OCR技术从图片输入到文字输出的完整处理链条,打破了"AI黑箱"的简单认知。
网络安全领域的流量分析工作正面临效率瓶颈。传统分析方法高度依赖人工操作,分析过程缺乏系统性沉淀,导致重复性工作频发。HuggingFists系统创新性地提出"分析链路化"解决方案,通过可视化算子拖拽构建标准化分析流程,将原本分散的操作步骤转化为可复用、可观察的自动化链路。该系统保留了专业分析工具的核心能力,但重构了使用方式:从逐层解析到字段提取的完整路径可被完整保存和调用,既避

脱敏算法篇使用阿里云数据脱敏算法为模板,使用算子平台快速搭建流程来展示数据遮盖脱敏是一种数据脱敏技术,它的主要目的是通过隐藏或替换敏感信息来保护数据安全,同时保持数据的其他特性不变,以便于数据的进一步使用和分析。这种脱敏技术适用于需要对敏感数据进行展示或分享的场景,例如在开发测试、数据分析、报告生成等过程中。在使用遮盖脱敏时,可以根据需要选择不同的脱敏规则,如保留特定位置的字符、替换为指定字符、字
