




- @c___c18
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Hugging Face--MLM预训练掩码语言模型方法
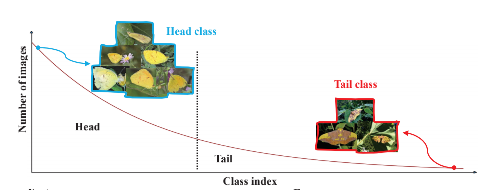
长尾分布在分类任务中会提到这个名,这是因为长尾分布这个现象问题会导致在训练过程中会出现出错率高的问题,影响了实验结果。这里要说的是,长尾分布是一种现象,有的地方说是一种理论或定律,我感觉这样说不太确切,因为长尾分布并非是一种普遍现象,不能将所有的数据分布或者现象都强加于长尾分布这个概念上。
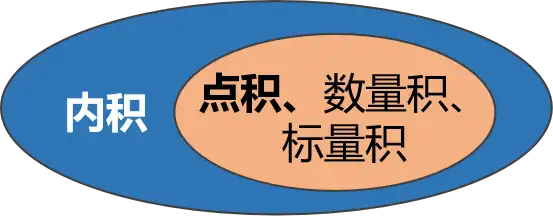
那么假设有两个向量:a=[a1a2a3];b=[b1b2b3]a=\left[\begin{array}{c}a_1\\a_2\\a_3\end{array}\right];b= \left[\begin{array}{c}b_1\\b_2\\b_3\end{array}\right]a=a1a2a3;b=b1b2b3欧几里得空间(Euclidean space)是内积空间
Hugging Face--MLM预训练掩码语言模型方法
这里整理一些PyTorch单机多核训练的方法和简单原理。

长尾分布在分类任务中会提到这个名,这是因为长尾分布这个现象问题会导致在训练过程中会出现出错率高的问题,影响了实验结果。这里要说的是,长尾分布是一种现象,有的地方说是一种理论或定律,我感觉这样说不太确切,因为长尾分布并非是一种普遍现象,不能将所有的数据分布或者现象都强加于长尾分布这个概念上。
下图中简单介绍了RNN和self-attention的机制区别,首先是第一个区别就是,在下图中最后面的黄色的输出值在RNN中很难去考虑第一个的RNN的输入(当然双向的RNN也是可以实现的,或者改进的RNN,如LSTM),而在self-attention中是很容易去实现的。下面这张图片表示了在不同数据集上的效果图,发现,在数据集不大的情况下,CNN的效果是优于self- attention的,反之C
HDU 无题II在不同的行和列里,是将行和列看做成连个没有交集的集合,这里可以看成是二分图的匹配要求是将最大值与最小值的差值最小化,那就是通过二分进行枚举,不断地缩减它的上界与下界#include <iostream>#include <string>#include <cstdio>#include &