- @bruce__ray
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在模型压缩方面,前文中我们提到了一些在算法层面的压缩方法,如剪枝、稀疏等,爱芯元智联合创始人、副总裁刘建伟指出,低比特也是压缩模型的一个方法,而且是对硬件最友好(便宜)的方式。2023年3月,爱芯元智推出了第三代高算力、高能效比的SoC芯片——AX650N,依托其在高性能、高精度、易部署、低功耗等方面的优异表现,AX650N受到越来越多有大模型部署需求用户的青睐,并且成为业内首屈一指的Transf

先是少数用户提出质疑,随后大量网友表示自己也注意到了,还贴出不少证据。有人反馈,把GPT-4的3小时25条对话额度一口气用完了,都没解决自己的代码问题。无奈。这就引起不少人怀疑,OpenAI是不是为了节省成本,开始?两个月前GPT-4是世界上最伟大的写作助手,几周前它开始变得平庸。我怀疑他们削减了算力或者把它变得没那么智能。这就不免让人想起微软“出道即巅峰”,后来惨遭“前额叶切除手术”能力变差的事
保存 之后再次双击 startup.cmd 运行即可。找到 startup.cmd 脚本 双击。找到路径 nacos\bin。需要需改cmd启动脚本。

而且是目前对此方面研究最新的综述。

本次的程序设计主要内容是机器学习——识别足球和橄榄球,通过本次课程设计,我对机器学习有了进一步的认识与了解,但在编写运行代码的过程中,也经常会遇到报错,通过一次次的修正,代码的编写也更快了。我切身感受到,在学习python的过程中,实践尤其的重要,只有通过亲自操作,才会发现自己学习过程中的不足之处,这对于我学习python,非常的有帮助。

参数服务器模式从第一代 Alex Smola 在 2010 年提出的 LDA(文本挖掘领域的隐狄利克雷分配模型),到第二代 Jeff Dean 提出的 DistBelief,接着到第三代李沐提出的相对成熟的现代 Parameter Server 架构,再到后来的百花齐放:Uber 的 Horvod,阿里的 XDL、PAI,Meta 的 DLRM,字节的 BytePs、美团基于 Tensorlow

在原有的智能巡检事件报告中,给出的建议相对固定,不能全面地将所有可能涉及到的错误建议给出。结合利用大模型,可以针对性地对触发的告警错误给出建议,提高事件报告的可读性。出处。
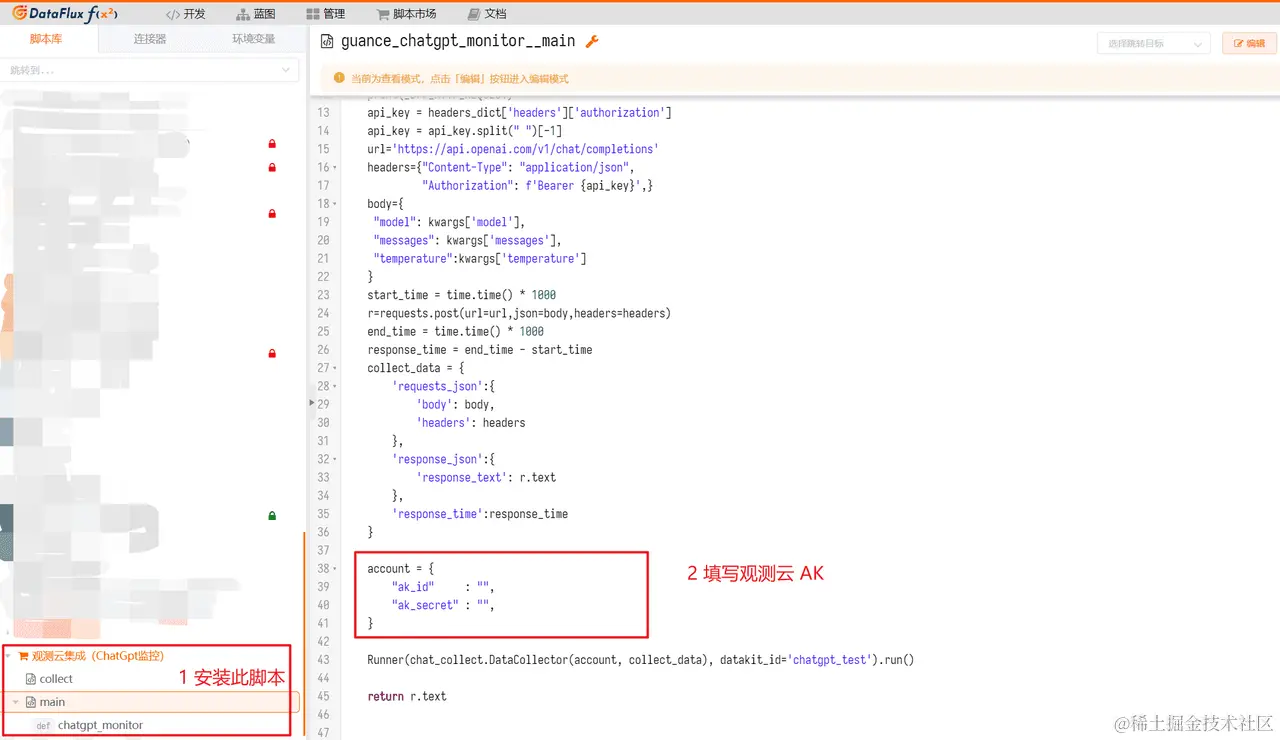
九号:总结开源可用的Instruct/Prompt Tuning数据440 赞同 · 4 评论文章**如有本文未提到的大模型,欢迎读者评论区留言。

langchain是一个开源项目。这个项目在GitHub上已经有45.5K个Star了。此项目由一位叫hwchase17的国外小哥在2022年底发布。我有理由相信,。