




- @baidu_41617231
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
别再把 AI 当聊天工具了!2025 年,真正能替你“动脑又动手”的 AI 智能体已悄悄上岗:从帮你一键扒视频文案,到自动做海报、剪书单号,甚至 15% 的职场决策都将由它们代劳。这篇零基础入门指南,只用 5 分钟带你穿越 70 年进化史,看懂智能体到底“智”在哪;再送 6 步搭建流程+100 个即用模板,让你零代码也能拥有自己的数字员工。
人工智能(Artificial Intelligence,简称AI),是一门旨在让机器模拟、延伸和扩展人类智能的计算机科学,核心是让系统具备感知、学习、推理、决策和交互的能力,而非单纯的程序化指令执行。主流分支包括深度学习(DL)(基于神经网络,处理图像、语音等复杂数据)、强化学习(通过试错奖励优化决策)、监督/无监督学习。3. 当下黄金期:生成式AI(如GPT、Midjourney)成为突破口,
1.3上传的压缩文件ollama-1inux-amd64.tar.zs,mv移动过来-->>一定注意路径:在o1lama所在路。#2.7换到别的目录下,就不能执行o11ama的命令-->>创建软连接:以后任意路径敲o11ama都有反应。#2.8现在可以用了,但是我们希望使用systemctl管理ollama服务。3.2 linux上[云服务器,虚拟机)-老师建议。3.1 win/mac机器[不建议
YOLOv8 是目前最新的 YOLO 模型版本,但是请注意,在撰写本回答时(2023年),YOLOv8 可能尚未发布或者还在开发中。YOLO 模型通常需要 Pytorch 框架,你可以使用 pip 来安装:pip install torch torchvision。如果 YOLOv8 还未发布或者有重大变化,请参考最新的官方文档和源代码。如果在克隆仓库或安装依赖时遇到问题,请检查 YOLOv8 的

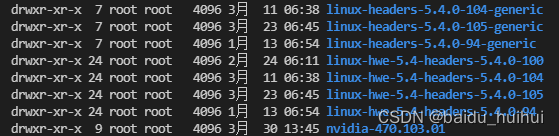
这是由于重启服务器,linux内核升级导致的,由于linux内核升级,之前的Nvidia驱动就不匹配连接了,但是此时Nvidia驱动还在,可以通过命令。如果失败了,别急,接着往下看>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>如果安装失败了,请跟者本文走>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>此时,我们需要把新安装的
aarch64-linux-gnu作为一种新的架构,在移动设备和嵌入式系统等领域得到了广泛应用。在开发过程中,需要搭建相应的开发环境,并且需要注意与arm-linux-gnueabi存在的不兼容性。虽然会遇到一些问题,但是技术社区提供了许多支持和理解,最终我们可以编写出高效、高质量的程序。

CNTK与深度强化学习笔记之二: Cart Pole游戏示例前言前面一篇文章,CNTK与深度强化学习笔记之一: 环境搭建和基本概念,非常概要的介绍了CNTK,深度强化学习和DQN的一些基本概念。这些概念希望后面还有文章继续展开深入:),但是只看理论不写代码,很容易让人迷惑。学习应该是一个理论和实践反复的过程。上一章的公式太多,这一章没有公式,只有代码。建议大家这两章来回看,把理论和代码对应起来。我
计算机视觉 - 语义分割 (semantic segmentation)人工智能被认为是第四次工业革命,google,facebook等全球顶尖、最有影响力的技术公司都将目光转向AI,虽然免不了存在泡沫,被部分媒体夸大宣传,神经网络在图像识别,语音识别,自然语言处理,无人车等方面的贡献是毋庸置疑的,随着算法的不断完善,部分垂直领域的研究已经落地应用。在计算机视觉领域,目前神经网络的应用主要有图像识
OpenClaw是一个强大的AI助手框架,支持多种消息平台接入。本文将详细介绍如何将OpenClaw接入微信,让你的AI助手可以在微信中使用。- OpenClaw官方文档: https://docs.openclaw.ai。解决:检查Gateway状态和binding配置。在 openclaw.json 中配置绑定。✅ 在微信中与AI助手对话。- 微信账号(需扫码登录)步骤4:重启Gateway。
神经网络架构搜索(NAS)今年也是火的不行,本文简单梳理一下个人觉得比较有代表意义的工作,如果有错误或者遗漏欢迎大家指出hhhh另外推荐一篇survey(虽然到处都在说这个,但我还是要推荐一下)Neural Architecture Search: A Survey大致按照时间线来,内容分为这么几块:大力出奇迹,平民化,落地1,大力出奇迹------------------------------