




- @ariesjzj
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
浏览器中可以在Preferences里的Network里设置。如果是终端下的软件(如apt-get)需代理上网,在终端输入命令:#http_proxy=http://yourproxyaddress:proxyport#export http_proxy之后运行要通过proxy上
1. 前言无论是AD/ADAS还是智能网联车,前视感知都是其最基础和重要的能力之一。自动驾驶(AD)是前几年的热门话题。今天虽然稍微降温下来一些,但仍是大家关注的重点之一,毕竟它是人类长久以来的梦想之一。众所周知,美国汽车工程师学会(SAE)将自动驾驶分为 L0~L5共六个级别。其中L3及以上允许由系统在限定或不限定条件下完成所有的驾驶操作;而L2及以下还是需要由人类驾驶员一直保持驾驶状态,因此.
前面的第一篇与第二篇分别介绍了背景与一些相关概念,这第三篇我们开始切入正题,看下现代深度学习编译器中的自动调优(Auto-tuning)方法。Schedule的自动生成,一类方法是基于解析模型(Analytical model),然后使用一些经验公式来产生解;另一类方法是多面体编译技术。它将循环嵌套迭代空间建模为多面体,然后用如整数规划等数学方法求出能提升局部性与并行性的循环变换;还有一类就是经验
前一篇《(一)大话深度学习编译器中的自动调优·前言》介绍了深度学习编译器及早期算子自动调优的背景,在接下去更深入地聊自动调优具体方法之前,在这篇中想先聊下两个与之密切相关的重要基础概念:领域专用语言(Domain-specific Language,DSL)与中间表示(Intermediate Representation,IR)。DSL与IR在整个深度学习编译器中的位置大体如下
深度学习计算框架中的自动化调优,尤其是高性能算子自动生成是这几年非常火的话题。这个系列的文章主要是对之前看到的零碎信息做个简单的总结。尽管,由于有些方向比较艰深,笔者懂得十分浅薄,文章在很多方面也只能蜻蜓点水。这是第一篇,权当是个引子。
2025年底DeepSeek V3发布炸场,几乎为业界之后的LLM优化方向定了调,尤其是大规模推理优化方面。在DeepSeek V3问世快一年之际,这里简单整理总结一下业界与之相关的推理优化技术。
深度学习相较传统机器学习模型,对算力有更高的要求。尤其是随着深度学习的飞速发展,模型体量也不断增长。于是,前几年,我们看到了芯片行业的百家争鸣和性能指标的快速提升。正当大家觉得算力问题已经得到较大程度的缓解时,大语言模型(LLM, Large language model)的兴起又带来了前所未有的挑战。
DeepSeek V3的网络结构基本沿用了DeepSeek V2,采用了MLA和DeepSeekMoE两大特性。本文主要涉及MLA(Multi-Head Latent Attention)。抛开维度变化,DeepSeek V3与V2在MLA结构上差别不大。详细请参见官方论文《DeepSeek-V3 Technical Report》和《DeepSeek-V2: A Strong, Economic
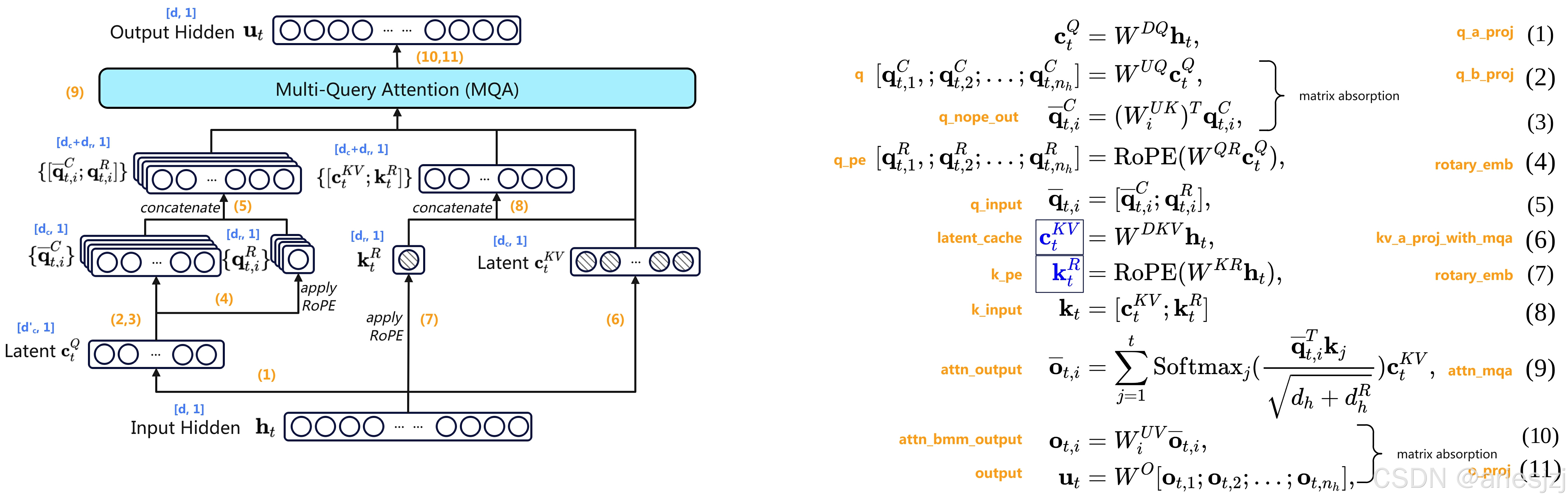
2025年底DeepSeek V3发布炸场,几乎为业界之后的LLM优化方向定了调,尤其是大规模推理优化方面。在DeepSeek V3问世快一年之际,这里简单整理总结一下业界与之相关的推理优化技术。