- @anda0109
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于阿里新开源的模型Qwen3,用相对少的参数获得了更高的性能,将会进一步降低模型的使用成本。这将进一步促进大模型应用的发展。同时,思考和非思考模式合二为一,不管对于使用体验还是部署成本也是一个重大的进步。还有,工具调用支持能力,对于Agent极其重要。虽然在我的测试中存在瑕疵,相信官方版本中会解决这个问题。好了,Qwen3的分享就到这里。今天的Qwen3力压deepseek,同样期待明天deep

Llama.cpp 是一个开源的、轻量级的项目,旨在实现 Meta 推出的开源大语言模型 Llama 的推理(inference)。Llama 是 Meta 在 2023 年开源的一个 70B 参数的高质量大语言模型,而 llama.cpp 是一个用 C++ 实现的轻量化推理端解决方案,适用于运行和测试 Llama 模型。1.轻量化:llama.cpp 是一个非常轻量级的项目,代码简洁且易于编译,

摘要:作者分享了自己从接触DeepSeek AI到全职投入AI创业的历程。春节期间被AI推理能力吸引后,经历了本地部署模型、购买工作站等探索,最终开发出智能体平台ZAI(Zero to AI)。平台包含模型管理、工具管理、知识库管理和智能体编排四大功能模块,支持多种大模型接入和RAG应用开发。目前已完成线上部署(zycdai.com),未来计划扩展工具库、开发通用模板智能体并持续优化性能。文章记录

Llama.cpp 是一个开源的、轻量级的项目,旨在实现 Meta 推出的开源大语言模型 Llama 的推理(inference)。Llama 是 Meta 在 2023 年开源的一个 70B 参数的高质量大语言模型,而 llama.cpp 是一个用 C++ 实现的轻量化推理端解决方案,适用于运行和测试 Llama 模型。1.轻量化:llama.cpp 是一个非常轻量级的项目,代码简洁且易于编译,
前面在我们使用langchain等框架做多工具调用的时候,我们不清楚具体的交互流程。LLM的推理过程是怎么样的,是一次做完规划还是逐个调用工具。我们今天直接使用openai的接口,用原始的写法来看它具体执行的过程是怎样的。

2025年已经悄然过去,回望这一年,AI不再是科幻电影里的概念,而是真真切切地走进了我们的生活。从年初的"Deepseek火爆全球"到年末的"Manus被Meta收购",整个AI圈简直像一场全年无休的“神仙打架”。今天,我们就来盘一盘2025年最值得关注的10大AI事件,看看有哪些让我们惊呼的瞬间!

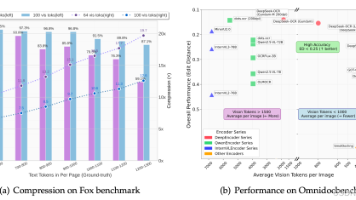
DeepSeek-OCR 突破传统OCR局限,实现图像到文本的高效转换。这项技术不仅能精准还原文档内容,还创新性地将图像作为文本压缩媒介,100个视觉token可还原近1000字文本,准确率达97%。其核心在于新型视觉编码器和30亿参数语言模型的协同工作,支持多语言、公式、图表等复杂内容解析。更深远的意义在于,它为大模型提供了模拟人类记忆机制的新思路——通过控制图像分辨率和token数量实现渐进式
摘要: 《上下文工程:构建高效智能体的新兴艺术》探讨了AI领域从提示词工程向上下文工程的演进趋势。文章指出,随着大语言模型应用从单次交互转向长期运行的智能体系统,优化上下文token集合成为关键挑战。作者分析了上下文工程的必要性,强调LLM存在"注意力预算"限制,长上下文会导致信息检索能力下降。文章提出了有效上下文的构成要素:精炼的系统提示、设计良好的工具集和代表性示例,并介绍
总的来说,MiMo-7B如果是6个月前发,可能算得上推理模型的顶流。今天发,应该不会引起太多关注。对于我们普通的推理模型使用者,也不用关注这个模型。Deepseek-R1、Qwen3系列4b以上模型,任一个性能都比它要好。他的价值在于将探索过程公开,使用推理数据做预训练,使基础模型天然具备推理潜力,同时在强化学习奖励机制和性能方面做了一系列优化。为开源社区提供见解和思路,也是一种贡献。深度探索AI

Coqui TTS是一个开源的文本转语音(TTS)工具包,旨在提供高质量、灵活且易于使用的语音合成解决方案。它由 Mozilla 的 TTS 项目发展而来,并在社区的支持下不断改进和扩展。Coqui TTS 支持多种语言、模型架构和声码器,适用于从研究到生产的各种场景。