




- @abcafdsgr123456789
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大厂性能优化 10大顶奢方案

一篇打通微服务架构,Nacos + Gateway + Redis + MySQL + Docker

本文详细阐述了MongoDB数据库的安装过程,从准备工作到成功安装,为初学者提供了清晰的指导。首先,介绍了安装MongoDB前需要准备的环境,包括操作系统版本要求、内存和存储空间等。接着,详细说明了MongoDB的安装步骤,包括下载安装包、解压文件、配置环境变量、创建数据目录等。此外,还介绍了如何启动MongoDB服务以及验证安装是否成功的方法。通过本文的指导,读者可以轻松地完成MongoDB的安

微服务回归单体,代码行数减少75%,性能提升1300%
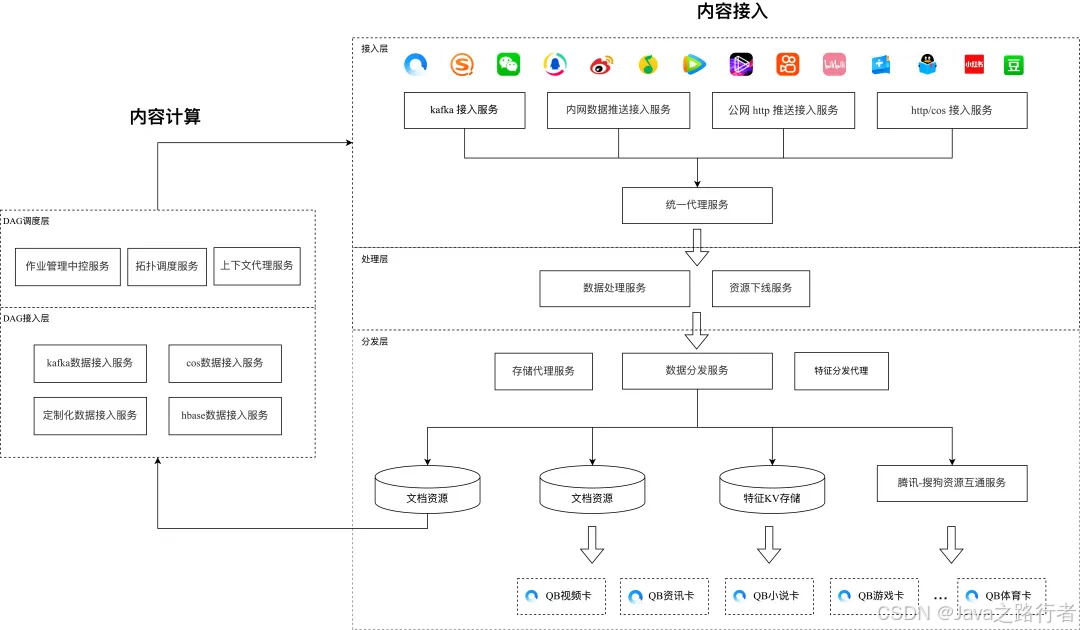
查询分离架构是解决大数据量查询性能问题的有效方案,但需要综合考虑数据一致性、系统复杂度和运维成本。通过合理的架构设计 + Elasticsearch的深度优化,可以构建出支撑千万级数据的高性能查询系统。b、数据同步消费者(DataSyncConsumer.java)a、数据写入服务(DataWriteService.java)✅ 数据需要频繁更新:所有数据都可能被修改(区别于冷热分离)✅ 数据查询
数据脱敏的 3 种常见方案
安装之前先把客户端工具instantclient_12_1拷贝到一个没有中文或空格的目录中,比如我直接拷贝到D盘目录下1.安装PLSQL Developer(安装目录不能有中文或空格,否则连接不上)2.PLSQL Developer远程连接oracle1).在弹出的登录窗口中点取消,Tools->>Preferences2).从虚拟机中的oracle安装目录中找到 tns...