




- @Sunshine_XX
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
存储和检索历史交互信息的能力,支持短期上下文记忆与长期知识库存储[来源:CSDN博客][https://blog.csdn.net/csdnnews/article/details/148101944]:跨会话保持用户意图理解,支持任务断点续接[来源:CSDN博客][http://m.toutiao.com/group/7538989867523457575/?upstream_biz=douba
本系列文章是针对《昇思MindSpore技术公开课》的学习心得和体会,文章产出用于参加【第五届MindCon极客周】。《昇思MindSpore技术公开课》包含了两期大模型专题,共包含十七课。课程结合华为自研机器学习框架昇思MindSpore,课程由浅入深,对想要学习机器学习特别是大模型技术的同学比较友好。建议对大模型的研究充满热情的同学可以观看学习一下。以下分享内容是按照本人对于学习进度的课程记录

可以实现代码翻译、解释的功能,涵盖语言种类繁多。

预测下一个单词的模型。
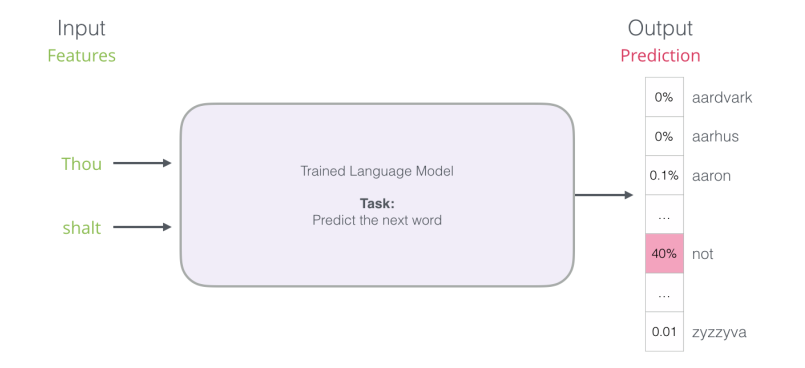
和BERT类似,GPT-1同样采取pre-train + fine-tune的思路:先基于大量未标注语料数据进行预训练,后基于少量标注数据进行微调。但GPT-1在预训练任务思路和模型结构上与BERT有所差别。
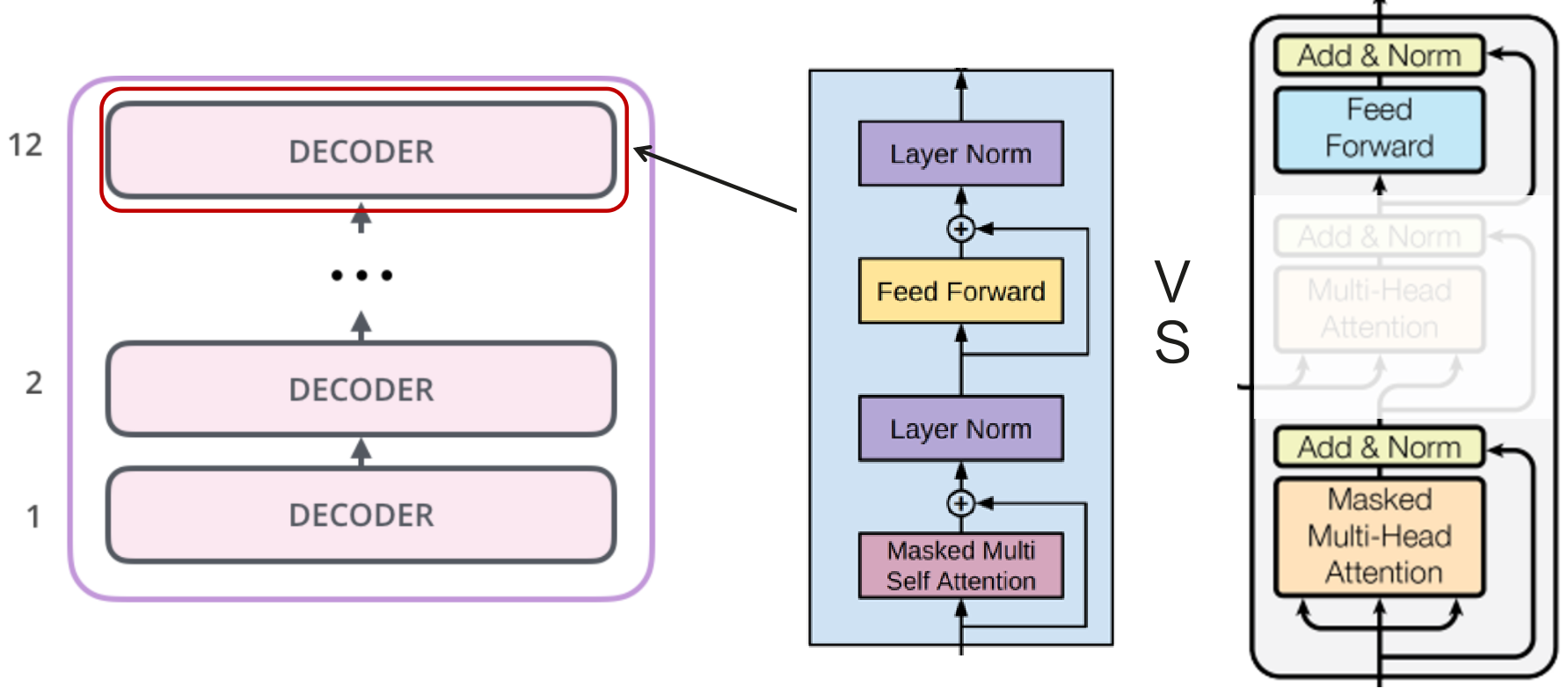
word2vec/Glove将离散的文本数据转换为固定长度的静态词向量,后根据下游任务训练不同的语言模型;ELMo预训练模型将文本数据结合上下文信息,转换为动态词向量,后根据下游任务训练不同的语言模型;BERT同样将文本数据转换为动态词向量,能够更好地捕捉句子级别的信息与语境信息,后续只需对BERT参数进行微调,仅重新训练最后的输出层即可适配下游任务;GPT等预训练语言模型主要用于文本生成类任务,

关键:利用超大规模的集群训练大模型。
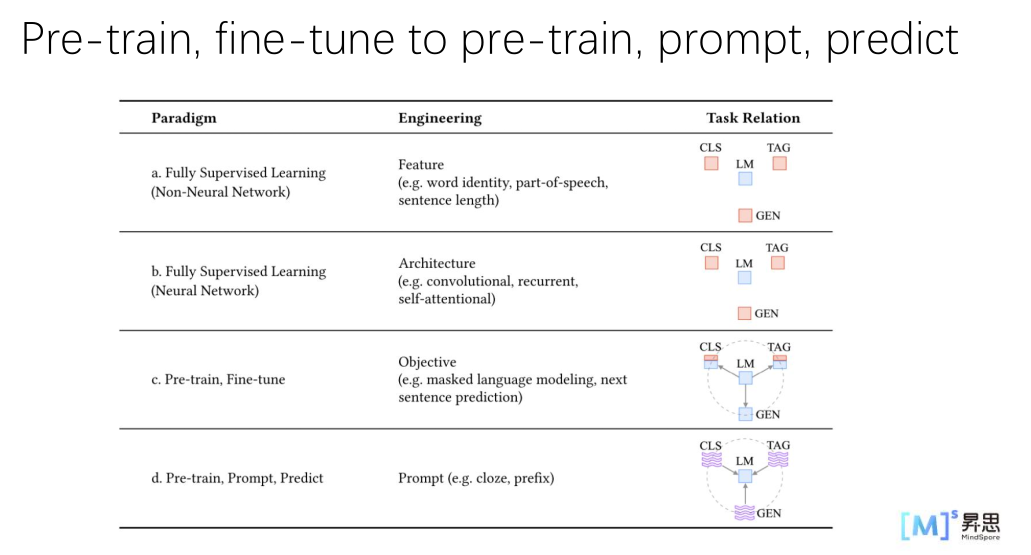
Pre-Train, Fine-tune的挑战两个训练阶段存在gap,导致少样本学习能力差,容易过拟合如果为了一个任务就要去finetune一个模型,开销是非常大的NLP任务的第四范式:Pretrain-Finetune-Propmt-Predict基于prompt的分类任务。
技能是 OpenClaw 的能力扩展包,可以让 AI 执行特定任务,如:📊 数据分析📝 文档处理🔍 信息检索🤖 自动化工作流步骤:创建技能目录编写 SKILL.md重启Gateway测试技能在对话中输入触发指令即可。
技能是 OpenClaw 的能力扩展包,可以让 AI 执行特定任务,如:📊 数据分析📝 文档处理🔍 信息检索🤖 自动化工作流步骤:创建技能目录编写 SKILL.md重启Gateway测试技能在对话中输入触发指令即可。