- @SDFsoul
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AstrBot + NapCat:轻松搭建QQ智能机器人 摘要:本文介绍如何使用AstrBot和NapCat快速搭建QQ智能机器人。AstrBot是一个支持多种AI模型的开源聊天机器人框架,而NapCat则负责将QQ消息转换为标准协议。通过Docker一键部署(支持Windows/Linux),用户可快速实现QQ机器人的自动回复功能。部署完成后,只需配置NapCat登录QQ账号并关联AstrBot

AstrBot + NapCat:轻松搭建QQ智能机器人 摘要:本文介绍如何使用AstrBot和NapCat快速搭建QQ智能机器人。AstrBot是一个支持多种AI模型的开源聊天机器人框架,而NapCat则负责将QQ消息转换为标准协议。通过Docker一键部署(支持Windows/Linux),用户可快速实现QQ机器人的自动回复功能。部署完成后,只需配置NapCat登录QQ账号并关联AstrBot
WebAssembly 与 Rust 的完美结合:构建高性能浏览器图像处理器 本文探讨了如何利用 Rust 和 WebAssembly 突破 JavaScript 性能瓶颈,实现浏览器端的高效图像处理。通过构建一个完整的图像灰度化应用案例,文章深入分析了: 技术选型优势 WASM 作为 JS 的性能补充,专攻 CPU 密集型任务 Rust 凭借无 GC、零成本抽象特性,生成体积小、性能高的 WAS

本文通过构建一个基于Rust异步生态(tokio)的TCP聊天室,探讨了Rust在高并发网络编程中的独特优势。传统语言(如C++/Java/Go)在性能、安全性和开发效率之间难以平衡,而Rust通过“无畏并发”理念,结合async/await和tokio运行时,实现了零成本抽象与编译时并发安全。 文章详细解析了聊天室的核心实现: 异步模型:利用tokio的多线程运行时和broadcast通道实现高

这篇文章介绍了一个为ClaudeCode设计的根提示词模板CLAUDE.md,该模板由博主赵纯想提炼优化。它构建了一个三层次的认知架构(现象层、本质层、哲学层),将AI角色定位为代码医生、侦探和诗人的三位一体。模板包含代码设计哲学(如简化原则、实用主义)、质量指标(文件规模限制)、代码坏味道检测机制,并强调架构文档CLAUDE.md作为系统记忆的重要性。最终目标是实现从问题修复到设计理解的认知跃迁

本文介绍了使用openJiuwen agent-core框架开发AI Agent的实践。第一部分通过5分钟构建"Hello World"示例,展示了框架的核心概念和基本工作流程。第二部分进阶开发了一个"毒舌文档排版助理",能够自动提取文本要点并给出尖锐点评。文章详细讲解了从环境配置、组件搭建到工作流连接的全过程,展示了该框架组件化设计、架构清晰的特性,适合快

本文介绍了通过ClaudeCode实现"Vibe Coding"的编程新范式,即无需打开编辑器即可完成全流程开发。重点分析了ClaudeCode的5大核心功能:升级的Claude 4模型、Subagents分工系统、MCP交互协议、CLAUDE.md规范文件和Skills技能库。作者以紫微斗数命理系统开发为例,展示了如何解决AI训练数据不足和上下文管理两大难题:通过conten

Rustpad是一款基于Rust构建的轻量级实时协作编辑器,支持多人同时编辑、无需账号登录、可选端到端加密。本文介绍了如何通过Docker快速部署Rustpad汉化版,并结合cpolar内网穿透工具实现公网访问。部署仅需创建docker-compose.yml文件并运行容器,即可在本地3030端口启动服务。通过cpolar将本地端口映射到公网,团队成员即可通过固定链接实时协作编辑文档,支持Mark

本文介绍了如何通过Docker部署MiGPT GUI服务,将小爱音箱接入AI大模型(以阿里云百炼为例),实现更智能的语音交互。方案无需更换硬件,通过中间服务连接现有设备与大模型,支持自定义角色设定、语音合成和远程管理。部署过程包括:1)Docker一键安装;2)配置小米账号和设备信息;3)接入大模型API;4)设置TTS语音服务;5)解决登录验证问题;6)调整人设参数;7)使用cpolar实现远程
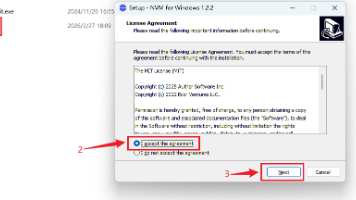
本文介绍了如何在Windows系统上搭建Remotion视频创作环境,通过React框架实现代码化视频制作。主要内容包括: 安装Node.js环境,配置nvm管理多版本 安装FFmpeg视频处理工具 初始化Remotion项目,使用React编写视频 通过自然语言让AI生成视频脚本 将本地预览穿透到公网分享 Remotion将视频制作转变为代码编写过程,支持精准控制每一帧动画,并能与AI工具无缝集