




- @Prettybritany
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先,使用BLIP2、GRIT、Segment Anything对图像生成Image Caption, Dense Caption, and Semantic Mask,然后将它们喂到chatgpt来生成文本描述text,再将text输入到frozen的BLIP2得到文本特征,最后,将text的特征concat作为q与图像特征计算cross attention再解码。,1、2、3是分开描述,4、5
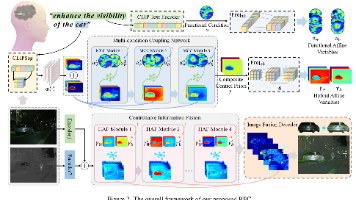
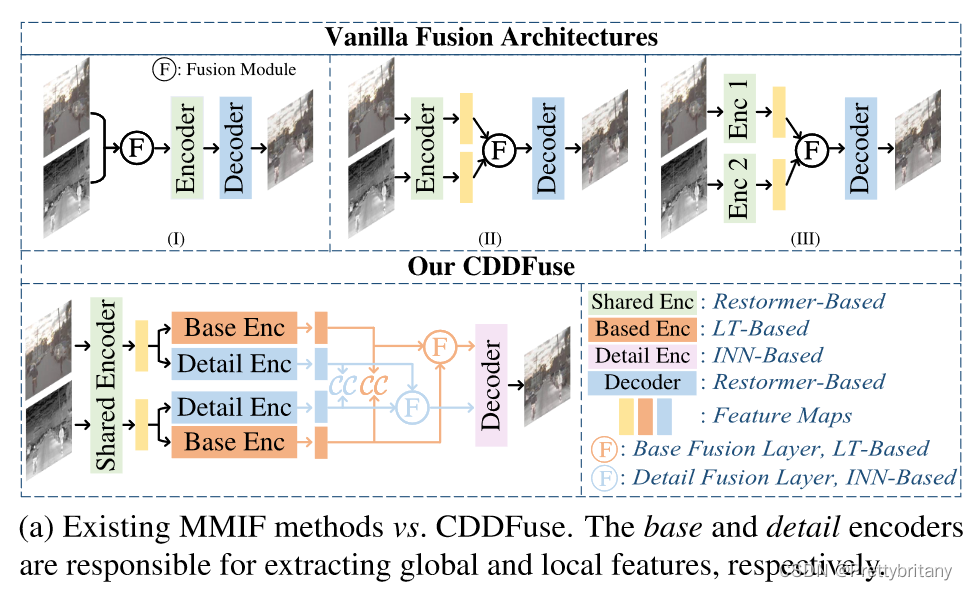
这个损失项的动机是,根据我们的 MMIF 假设,分解后的特征 {ΦB I , ΦB V } 将包含更多模态共享信息,例如背景和大规模环境,因此它们通常是高度相关的。通过扁平化前馈网络的结构,扁平化了 Transformer 块的瓶颈,LT 块缩小了嵌入,以减少参数数量,同时保持相同的性能,满足我们的期望。显然,我们的方法更好地整合了红外图像中的热辐射信息和可见图像中的详细纹理。例如,在图1a中,(
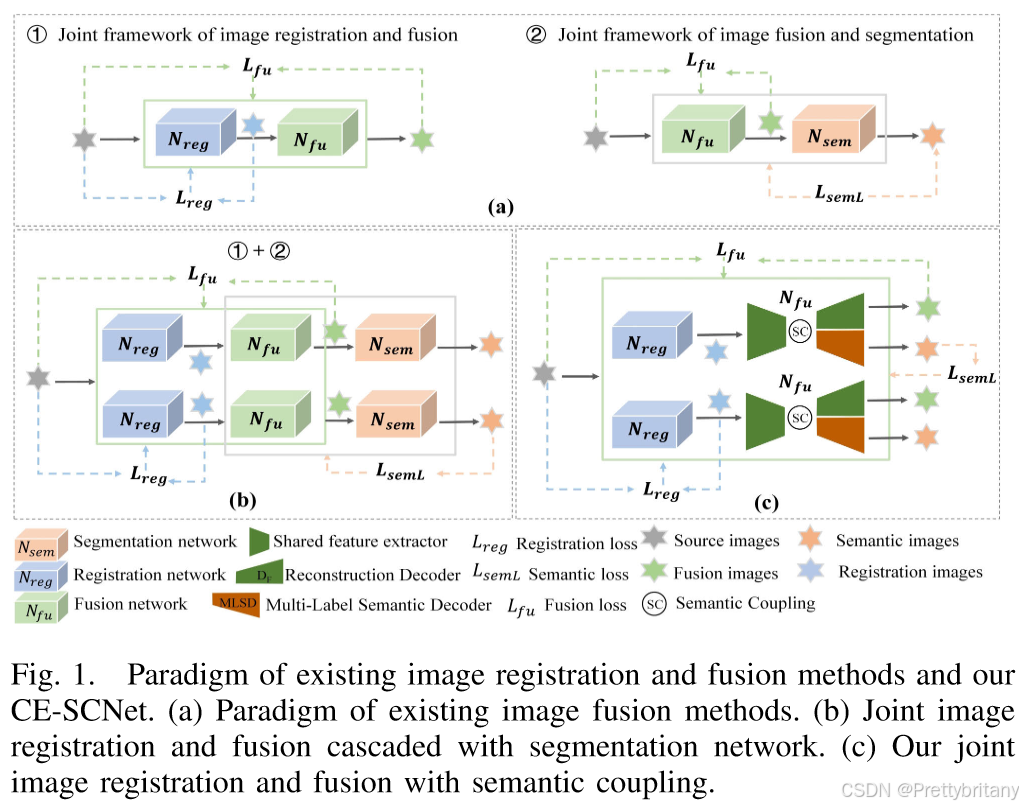
1.引入语义信息:考虑到的需求,将引入融合网络中。2.联合训练:利用分割网络[52]产生的通过反向传播指导融合网络的训练,迫使融合图像包含更多语义信息。m 表示第 m 次迭代。随着训练的进行,β逐渐增大,这是因为随着迭代次数的增加,分割网络更好地拟合融合模型,并且语义损失可以更准确地指导融合网络训练。3.设计梯度残差密集块(GRDB):为了满足高级视觉任务的需求,开发了一种基于梯度残差密集块(GR
首先你要确认自己连的节点不属于以下任何一个国家。如果你确定你连的节点不属于上图的任何一个国家还是显示not available,那么有两种情况。一.你的科学上网工具的设置。例如我用的是ssr,我打开了服务器负载均衡,它就会自动的在我所有的节点里选择最好的节点进行连接,我以为自己连的是美国的节点,其实它可能已经给我换到了香港、俄罗斯的节点。关闭负载均衡后,连接任意一个非上图国家的节点就OK了。二..