- @Maxwell_Newton
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
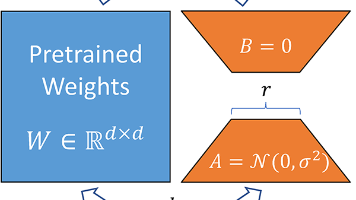
一个已经训练好的LLM一般有几十,甚至几百B的参数,想增加数据重新训练的开销是不可接受的,即使是专业计算卡,如果不是大厂的集群,也是训不起来的。我们现在只有一个AMD 48G计算卡,只能尝试LoRA微调来重训模型。LoRA的数学操作是,对于每个要微调的参数矩阵,假设原本是d * d的,我们不去更新这个大矩阵的参数,而是弄两个小矩阵a,b,大小分别为d* r,r * d,r通常很小,比如这里我们设为
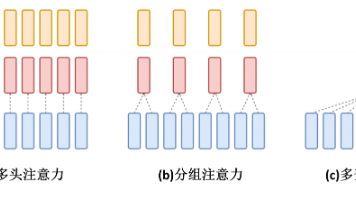
大模型推理引擎不会每个请求独立推理,会把一些请求组成一个batch进行批处理,这是推理引擎提升吞吐率的关键。使用批处理后吞吐相比单请求会大幅提升,但还是有个问题,如下图,一个batch=4的批处理,开始推理后,会运行到所有序列推理都结束了才会结束,因此整个batch的推理时间取决于最慢的序列,在这里是第二行的序列,到T8才出现END符号其他序列即使已经推理完了,也只能等着,并且在这个batch结束

模型参数,基本没有增加,只有7B,13B,70B三个版本和前代差不多,但是训练数据增加了,从1T增加到2T,这正是Llama-1训练策略的延续数据量有更大的版本了,但仍然保持了小版本,分别有8B,70B,400B版本,对标GPT-4,相比Llama-2性能有了大的飞跃。这得益于训练数据从2T提升到了15T。
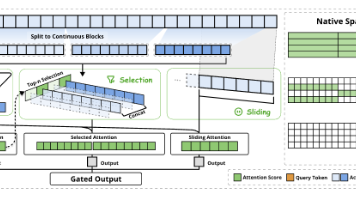
NSA 的核心思想是将原本全局的 Attention 分解为三个优势互补的稀疏分支,以极低的 KV Cache 占用保留长文本的表征能力:Compressed Attention(压缩注意力)做法:将历史的 KV 序列按照固定的 Block 大小(例如每 128 个 Token 一个块)进行划分,通过一个简单的 Pooling 或小型网络进行粗粒度压缩。作用:用极小规模的 KV 表达全局的“背景宏
但GPT-3模型是2020年发布的,到ChatGPT服务问世还过去了接近三年,这是因为此时的模型在指令遵循方面很差,类似于一个强大的野兽,不受人类控制。最终的测试效果,也证明了扩大参数规模的有效性,GPT-2不再像GPT-1一样需要对输入进行预处理,然后做微调,才能处理特定任务了,直接把在输入基础上用自然语言描述需要做的任务,就能在文本翻译,文本分类等特定任务上去的超过专用模型的效果,这就是所谓的
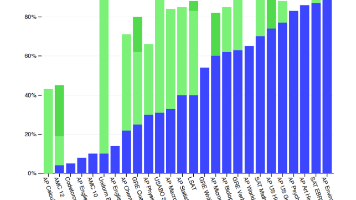
但GPT-3模型是2020年发布的,到ChatGPT服务问世还过去了接近三年,这是因为此时的模型在指令遵循方面很差,类似于一个强大的野兽,不受人类控制。最终的测试效果,也证明了扩大参数规模的有效性,GPT-2不再像GPT-1一样需要对输入进行预处理,然后做微调,才能处理特定任务了,直接把在输入基础上用自然语言描述需要做的任务,就能在文本翻译,文本分类等特定任务上去的超过专用模型的效果,这就是所谓的
但GPT-3模型是2020年发布的,到ChatGPT服务问世还过去了接近三年,这是因为此时的模型在指令遵循方面很差,类似于一个强大的野兽,不受人类控制。最终的测试效果,也证明了扩大参数规模的有效性,GPT-2不再像GPT-1一样需要对输入进行预处理,然后做微调,才能处理特定任务了,直接把在输入基础上用自然语言描述需要做的任务,就能在文本翻译,文本分类等特定任务上去的超过专用模型的效果,这就是所谓的
一个已经训练好的LLM一般有几十,甚至几百B的参数,想增加数据重新训练的开销是不可接受的,即使是专业计算卡,如果不是大厂的集群,也是训不起来的。我们现在只有一个AMD 48G计算卡,只能尝试LoRA微调来重训模型。LoRA的数学操作是,对于每个要微调的参数矩阵,假设原本是d * d的,我们不去更新这个大矩阵的参数,而是弄两个小矩阵a,b,大小分别为d* r,r * d,r通常很小,比如这里我们设为
Softmax 算子(Softmax Operator)是深度学习和机器学习中最常用的激活函数之一,主要用于将一个包含任意实数的向量(通常称为 Logits)映射为一个概率分布。对于一个包含NNN个元素的输入向量xx1x2xNTxx1x2xNT,Softmax 算子会将其映射为相同维度的输出向量ss1s2sNTss1s2sNT。对于输出向量中的第iii个元素sis_isisiSoft
实际上我们可以自定义一个ROCm算子,并在torch里调用它,这样可以用py的语法,ROCm的性能。