




- @LTKnt77
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
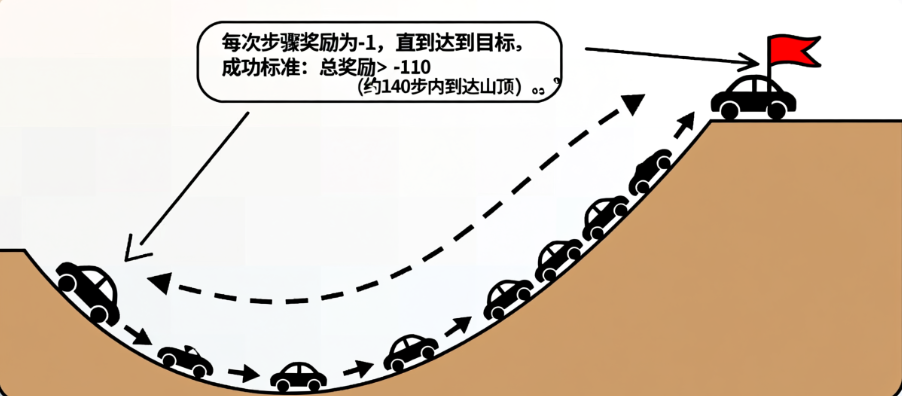
MountainCar 是一个经典的强化学习环境,目标是通过控制小车的加速方向(向左/向右/不加速),使其从山谷底部到达右侧山顶(旗帜位置)。挑战:小车动力不足,无法直接冲上坡,需要利用重力在两侧坡面之间来回摆动积蓄能量。成功标准:总奖励 > -110(约 140 步内到达山顶)
在AI Agent的研发圈子里,一个新概念正在被反复提起:Harness Engineering,中文可以翻译成“驾驭工程”。它指的是在AI系统中,除了模型本身之外,所有用来保障系统稳定交付、可靠执行任务的工程组件总和。如果说模型是引擎,那Harness就是方向盘、刹车、燃油系统和仪表盘,没有它,再强的引擎也无法安全上路。我们不妨先回顾一下AI工程化的三个演进阶段,这能帮我们更好地理解Harnes

推理任务的数据标注是一场对逻辑严谨性的极致追求。它要求我们不仅设计出引导正确思考路径的思维链,还需对思考过程本身进行细粒度监督,并通过严格的培训与量化体系确保每一步标注都经得起逻辑推敲。从依赖昂贵人工的PRM800K,到自动化高效的OmegaPRM,再到领悟“推理模式”即可的PARO框架,技术演进的核心始终是:如何以可持续的成本,为模型注入更可靠、更深刻的推理能力。
MountainCar 是一个经典的强化学习环境,目标是通过控制小车的加速方向(向左/向右/不加速),使其从山谷底部到达右侧山顶(旗帜位置)。挑战:小车动力不足,无法直接冲上坡,需要利用重力在两侧坡面之间来回摆动积蓄能量。成功标准:总奖励 > -110(约 140 步内到达山顶)
从之前的实践来看,结构化解析的效果是明显强于常规的文件内容提取的。相对于常规的文件内容提取,结构化解析保留了文件的层级结构以及各个层级的标题信息,可以有效提升文档内容的召回率。常规 RAG 文件解析方案为了尽可能提升结构化解析能力,常规情况下会选择实现基础文件类型的结构化解析,其他文件尽可能转换为基础文件类型。而目前最常见适用于结构化解析的基础类型为 html 和 markdown。比如目前最常见
MountainCar 是一个经典的强化学习环境,目标是通过控制小车的加速方向(向左/向右/不加速),使其从山谷底部到达右侧山顶(旗帜位置)。挑战:小车动力不足,无法直接冲上坡,需要利用重力在两侧坡面之间来回摆动积蓄能量。成功标准:总奖励 > -110(约 140 步内到达山顶)
做这个对比分析,是为了更好地学习RAG文档解析环节。之前盲目地相信AI coding,没了解PDF解析原理,在批量解析PDF构建向量数据库后,通过检索发现并没有得到有效解析。用的工具是MinerU,进行版面分析,后退策略(若是MinerU不可用,现在看来根本没必要)使用PyMuPDF,在解析过程中一直反馈依赖安装问题,也就是magic-pdf一直报错(不存在,即使我已经安装了,但是因为版本原因读取
最近在学习RAG的文档解析板块,发现有太多工具可以使用。之前对比过一些常用的工具,后续发现对这些工具并没有太深入的学习使用方法,就比如docling,当时解析PDF发现不太理想,整体不如MinerU,但是不少博客的对比试验又表明docling也是非常强大的解析工具,更胜于MinerU,所以决定重新学习docling,也学者根据GitHub上的文档来一步一步掌握这个工具。docling项目地址:ht
做这个对比分析,是为了更好地学习RAG文档解析环节。之前盲目地相信AI coding,没了解PDF解析原理,在批量解析PDF构建向量数据库后,通过检索发现并没有得到有效解析。用的工具是MinerU,进行版面分析,后退策略(若是MinerU不可用,现在看来根本没必要)使用PyMuPDF,在解析过程中一直反馈依赖安装问题,也就是magic-pdf一直报错(不存在,即使我已经安装了,但是因为版本原因读取
做这个对比分析,是为了更好地学习RAG文档解析环节。之前盲目地相信AI coding,没了解PDF解析原理,在批量解析PDF构建向量数据库后,通过检索发现并没有得到有效解析。用的工具是MinerU,进行版面分析,后退策略(若是MinerU不可用,现在看来根本没必要)使用PyMuPDF,在解析过程中一直反馈依赖安装问题,也就是magic-pdf一直报错(不存在,即使我已经安装了,但是因为版本原因读取