




- @LI_XIAO_XING
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先对多维特征进行解释:如有一个y,他的值由8个x(x1,x2,x3~~)决定,那么x就有8个维度。我们的linear所作的事就是y=wx+b,其中每一个量都是向量,因此可以处理多维度数据。如x有8个维度,y有一个维度,那么可以写成self.linear=torch.nn.Linear(8,1)内部过程就是:y(N*1),x(N*8)(表示y一维,x8维,总共有N个数据),那么w就是(8*1),矩

多模态扩散大语言模型(MDLLMs),这类模型通过并行掩码解码实现高效生成。他和GPT的自回归编码模式不同,是并行解码的。具体是怎么做的呢?
先通过 MUNIT 模型(无监督图像翻译)把人类演示视频逐帧转化为机器人视角的视频 —— 翻译后的视频可能有视觉伪影,缺少结构化关键信息,无法直接用于训练;接着用 Transporter 模型从翻译后的机器人视频中提取关键点轨迹(比如机器人末端、物体中心的运动轨迹);最后用这些轨迹作为强化学习的训练目标,让机械臂的关键点轨迹与目标轨迹尽可能一致,从而学会操作技能。经过上述训练,我们就得到了能准确提
表示算法效率的方法:增长率。计算方法:不要低阶项和常数项,只要高阶项。同阶函数:(g(n))={f(n) | 存在c1, c2>0, n0, 任意n>n0, c1g(n)<f(n)<c2g(n)}称为与g(n)同阶的函数集合。证明用定义,就像数学一样。注意:同阶符号中间有一个“H”,不要与低阶符号弄混。低阶函数:简记:中间有“H”的相当于是=,没有的相当于是<=。高阶
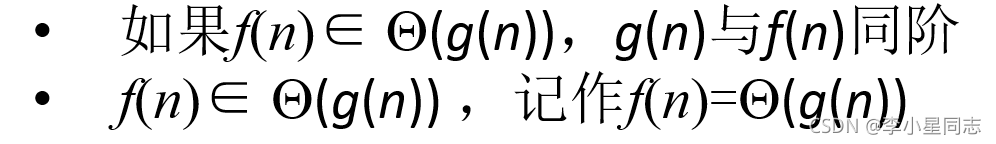
术语定义核心作用世界模型(World Model)学习环境动态的内部模型,形式化为部分可观测马尔可夫决策过程(POMDP),目标是估计状态转移函数 pθ(ot+1∣o≤t,a≤t)预测未来观测,支撑智能体决策视频扩散模型(Video Diffusion Model)基于扩散过程的生成模型,通过逐步去噪生成高保真视频,训练数据为互联网无动作标签视频提供丰富的物理先验(如物体运动规律、场景一致
PPO在线互动式优化,模型和环境(或 RM)实时交互产生奖励,通过优势估计和裁剪机制,逐步调整策略,适合 “没有现成标注、需要模型主动探索” 的场景(如机器人自主学习、从零训练的对话模型)。DPO离线偏好式优化,直接用现成的 “好坏回答对” 训练,通过对比概率比值让模型对齐偏好,还天然绑定参考模型防止退化,适合 “有大量人工 / AI 标注偏好数据、追求简单稳定” 的场景(如大模型对齐的量产阶段)
DINO ViT patch tokens + 可学习的 camera token(每帧1个)+ 4 个 register token。(Alternating-Attention):先帧内自注意力,再跨帧全局自注意力,循环 24 次。Tracking Head(CoTracker2):用跟踪特征完成任意点到全部帧的匹配。Dense Head(DPT):输出深度图、点云图、不确定性图、跟踪特征图。
AndroidWorld上的实验结果表明,EcoAgent有效地处理了复杂的移动任务,同时减少了MLLM的令牌消耗,从而降低了运营成本,并促进了边缘设备上的实际部署。可以看到,在plan agent提出了一个计划+每步计划的预期结果之后,假如操作结果一直符合预期的话,整个流程接下来都不需要云端模型了。只有出现了不符合预期的情况的时候,才会需要云端模型,把当前情况和他说一下,再让他修改一下计划。ap
VLA训练的时候要多几个epoch,不能像LLM一样1,2个就完事了。VLA意为:vision language action 模型,其中的v可以使用常规多模态模型的vision部分。使用的现成的数据集,但是做了修改。只要人为手动的数据集,使用的机器什么的都要统一,各种任务类型也要平均。Motion(移动):同样的东西和背景看起来差不多,不过东西的位置不太一样。优点基本上就是:模型小,开源,直接用
先通过 MUNIT 模型(无监督图像翻译)把人类演示视频逐帧转化为机器人视角的视频 —— 翻译后的视频可能有视觉伪影,缺少结构化关键信息,无法直接用于训练;接着用 Transporter 模型从翻译后的机器人视频中提取关键点轨迹(比如机器人末端、物体中心的运动轨迹);最后用这些轨迹作为强化学习的训练目标,让机械臂的关键点轨迹与目标轨迹尽可能一致,从而学会操作技能。经过上述训练,我们就得到了能准确提