- @JumpZard
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
项目概要之前我们已经通过动态分流把数据分到了我们想要的位置,为了方便后续内容的讲解方便,所以接下来我们可以把配置表的信息进行导入了,然后通过动态分流的方法,把数据发往对应的kafka主题或者是hbase的维度表中://配置信息表:CREATE TABLE `table_process` (`source_table` varchar(200) NOT NULL COMMENT '来源表',`ope
DWD层业务数据分流回顾一下之前业务数据的处理;首先把脚本生成的业务数据发送到MySql数据库中,在表gmall0709中可以看到数据:这里就是生成的对应数据表,然后通过Maxwell把数据输入到Kafka中,保存在ods_base_db_m主题中;此时我们需要把这个kafka主题中的数据进行过滤和分流处理,过滤处理很容易,这里我们过滤掉data为空,或者是长度<3的数据内容,当然这个数据过
这几天复习计网的东西去了~~不定期更新之所以单独将这个主题宽表拿出来讲,是因为他的设计过程非常具有代表性,可以参照这个表的设计方式去实现后续其他的主题宽表设计(后续有Flink Sql的实现过程、另讲);在该系列的第一篇文章中,我已经提高了各个层的设计目的;DWS层在本项目中的主要作用是为了ADS层的查询和后续可视化设计的,算是数据接口的直接数据来源,所以这里对实时性的要求很高,否则你再这里算个几
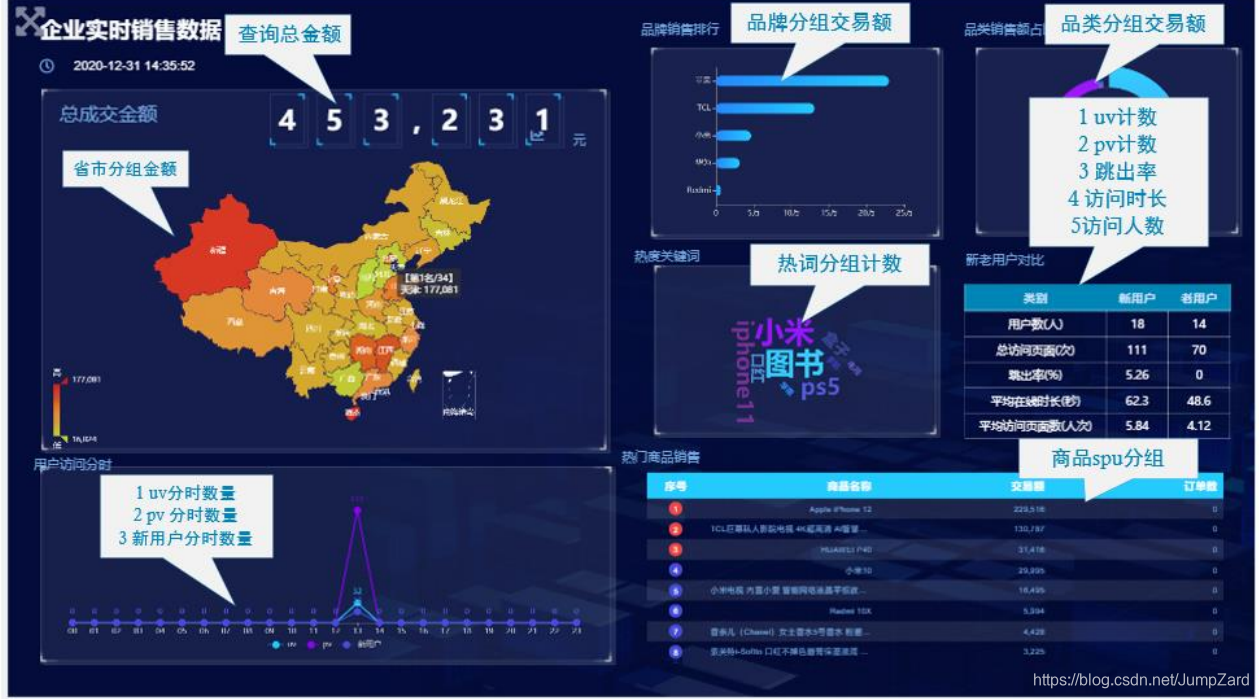
从这篇内容开始就是项目的正式过程了,接下来我将以思路和项目过程为主来进行讲解,部分过程我也会对代码部分内容进行讲解。前提条件:对应的hadoop集群要有,具体配置方法和版本见第一节内容;phoenix、clickhouse、springboot、redis等框架的使用,我会在用到的时候再介绍,也可以自己根据下载包里的文档内容进行了解,文章不做详细介绍。第一部分 日志采集日志生成这里采用模拟jar包
这几天复习计网的东西去了~~不定期更新之所以单独将这个主题宽表拿出来讲,是因为他的设计过程非常具有代表性,可以参照这个表的设计方式去实现后续其他的主题宽表设计(后续有Flink Sql的实现过程、另讲);在该系列的第一篇文章中,我已经提高了各个层的设计目的;DWS层在本项目中的主要作用是为了ADS层的查询和后续可视化设计的,算是数据接口的直接数据来源,所以这里对实时性的要求很高,否则你再这里算个几
项目整体思路和架构本项目主要参考尚硅谷的Flink实时数仓项目完成,最近又重新跑了一遍,项目整体我会在后续上传到码云中,也会同步更新到博客中来,里面不仅包含了整体代码和整个集群搭建过程,也包含了一些我自己的理解和测试过程希望大家能喜欢,以后我也会把我整个的大数据学习过程和笔记做一个分享。非常欢迎一起学习大数据的朋友,大家可以一起交流和学习。实时数仓分层思想这里采用的架构和离线数仓架构不同,整个项目