




- @Guzith
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
报告还涉及到AI在数学、物理科学、生命科学、地球环境科学、工程学、人类社会学中的应用进展,以及相关的政策。包含引言、核心AI技术、AI在数学、物理科学、生命科学、地球与环境科学、工程科学、人文社会科学等领域的应用,以及展望与政策建议。发表量全球领先(2024年达27.39万篇,占全球28.7%),在应用创新方面(专利、政策文件、临床试验引用)也处于领先地位。大语言模型(LLM)、强化学习、计算机视

这里对大模型评测需要关注的一些内容做了分类和细化,希望能带来一些借鉴参考。
一、性能评测工具1.深度学习框架自带的评测工具PyTorch:它提供了如库,该库包含了一系列用于评估模型性能的指标计算函数。例如,在分类任务中可以方便地计算准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 - score 等。以计算准确率为例,使用函数,只需将模型的预测结果和真实标签传入,就能快速得到准确率的值。TensorFlow:它有模块,提供了多种用于
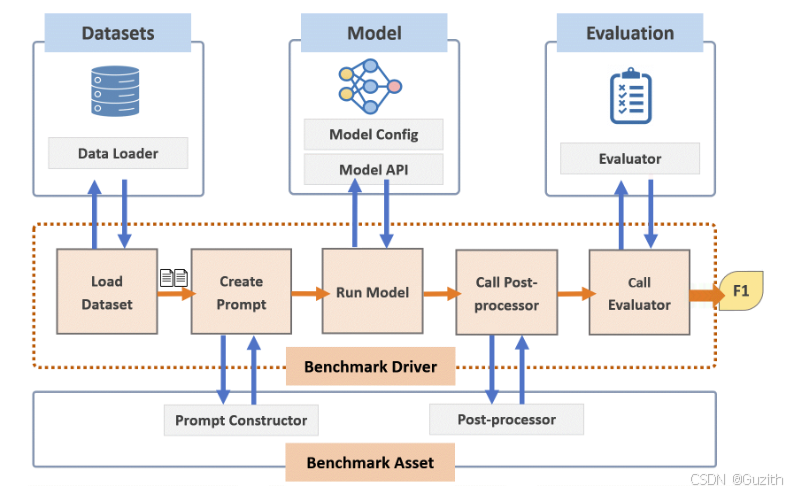
前面基本把整个基准评测体系讲完了。有了评测体系,可以按照步骤一步步去执行。不过在实际执行过程中还有许多细节需要注意,同时还有一些挑战需要我们去应对。这里简单做一下介绍,这样对大模型评测能有更进一步的认识。
准确率表示模型预测正确的样本占总样本数的比例,是一种衡量分类模型整体性能的指标。
明确评估的具体任务类型(如文本分类、问答系统等),并选定适当的评价指标(如准确率、F1分数)。确保这些指标能够全面衡量模型的各项能力。
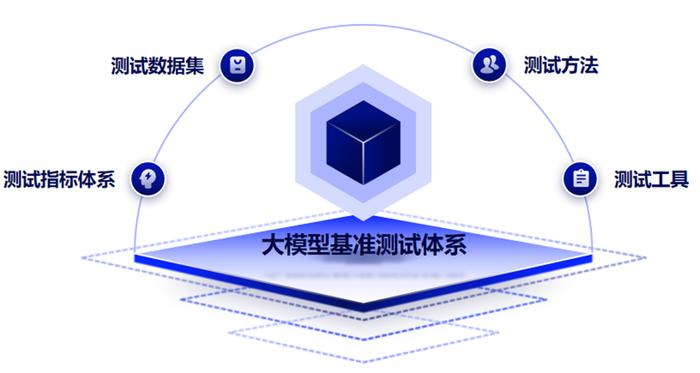
大模型能够协助我们完成各种任务,改变我们的生产和生活的方式,提高生产力,为我们带来便利,但同时使用过程中也伴随着诸多风险与挑战,如泄露隐私数据,生成带有偏见、暴力、歧视、违反基本道德和法律法规的内容,传播虚假信息等。因此对大模型能力及其不足之处形成更深入的认识和理解,预知并防范大模型带来的安全挑战和风险,需要针对大模型开展多方位的评测,一般也叫大模型基准测试。大模型基准测试体系涵盖了大模型的测评指
Meta 杨立昆团队“最难LLM评测榜”加州大学伯克利分校工具准确性评测。谷歌提出的指令理解测试。
整个过程采用 JSON 格式的消息进行数据传输,这样做的好处是确保了上下文在多次交互中得以保持,实现了“连续对话”的功能,而不仅仅是一次性 API 调用。:技术社区出现首批基于Claude 3.5 + MCP的应用案例,如通过MCP协议实现Claude与本地文件系统、数据库的自动化交互。通过这种架构,MCP 协议消除了传统上每种数据源都需要单独集成的繁琐步骤,使得 AI 应用能够通过统一的接口与各