




- @GUPAOAI
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Python 神经网络编程》是一本难得的 “零基础实战指南”,通过 “理论讲解 + 代码实现 + 实验优化” 的闭环,让复杂的神经网络技术变得通俗易懂。无论你是想入门 AI 的小白,还是希望亲手搭建第一个智能模型的爱好者,这本书都能为你提供清晰的路径和实用的工具,助力你在神经网络的世界中迈出坚实的第一步。《Python 神经网络编程》:零基础入门神经网络的实战指南t=P1C7t=P1C7t=P1C

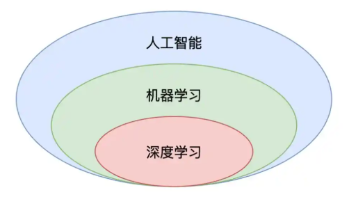
摘要:机器学习与深度学习的学习顺序应根据目标领域而定。处理表格等结构化数据建议从机器学习入手;若专注于图像或文本处理,则可直接学习深度学习,掌握线性回归和逻辑回归后快速转向神经网络实践。
本文系统介绍了使用PyTorch构建深度学习项目的完整流程,包括数据集加载、数据预处理、模型构造、训练与测试等关键环节。
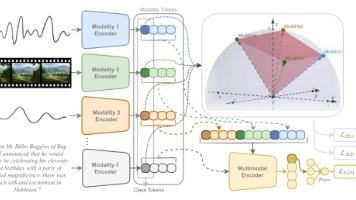
多模态学习让AI系统能像人类一样综合处理图像、文字、声音等多源信息,其核心技术包含两个关键环节:多模态对齐和多模态融合。对齐解决不同模态信息的对应关系,如CLIP模型通过对比学习建立图像与文字的语义关联;融合则关注如何整合多模态数据,包括早期融合、晚期融合和动态交互的交叉融合三种策略。现代Transformer架构凭借统一的token化处理和自注意力机制,为多模态学习提供了理想框架,推动了GPT-
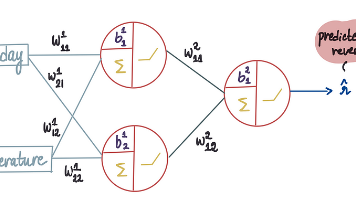
文章摘要:本文详细介绍了使用神经网络预测冰淇淋销售的实现过程。首先阐述了如何确定网络架构(1个隐藏层,2个神经元),并重点讲解了通过梯度下降法优化模型参数(权重和偏差)的方法。文章比较了暴力破解法、梯度下降法和随机梯度下降法的优缺点,指出梯度下降能有效寻找最优参数值,但随着数据量增大可能出现计算效率问题。最后简要提及了学习率设置的重要性及其他优化算法,为神经网络训练提供了系统性的方法指导。
最简单的、最适合拿来入门的计算机视觉算法是:跟踪一个有颜色的物体,比如一个粉色的球,我们首先记下球的颜色,保存最中心像素的RGB值,然后给程序喂入图像,让程序找最接近这个颜色的像素。事实上,如果不是盲人这类特殊群体,绝大多数人对外界信息的获取都是通过视觉完成的,而这个占比高达80%以上——这个比例并不是没有根据的,著名实验心理学家赤瑞特拉(Treicher)曾通过大量的实验证实:人类获取的信息的8
多模态学习让AI系统能像人类一样综合处理图像、文字、声音等多源信息,其核心技术包含两个关键环节:多模态对齐和多模态融合。对齐解决不同模态信息的对应关系,如CLIP模型通过对比学习建立图像与文字的语义关联;融合则关注如何整合多模态数据,包括早期融合、晚期融合和动态交互的交叉融合三种策略。现代Transformer架构凭借统一的token化处理和自注意力机制,为多模态学习提供了理想框架,推动了GPT-
其他软件论文,如排名第十五的scikit-learn(Python机器学习库)和排名第十八的DESeq2(RNA测序分析),因其开源和易用性,成为科学家不可或缺的工具。此外,2017年谷歌发表的Attention is all you need排位列七,论文中提出了著名的Transformer架构,成为ChatGPT等大模型的核心。然而,令人意外的是,那些广为人知的科学发现:从mRNA疫苗和CRI
摘要:机器学习与深度学习的学习顺序应根据目标领域而定。处理表格等结构化数据建议从机器学习入手;若专注于图像或文本处理,则可直接学习深度学习,掌握线性回归和逻辑回归后快速转向神经网络实践。
摘要:机器学习与深度学习的学习顺序应根据目标领域而定。处理表格等结构化数据建议从机器学习入手;若专注于图像或文本处理,则可直接学习深度学习,掌握线性回归和逻辑回归后快速转向神经网络实践。