
写文章




- @CLanMua
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
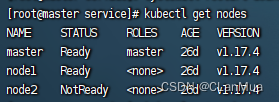
K8S node节点NotReady排错方法
K8S node节点NotReady排错方法
Springboot集成kafka,程序重启后,让消费者跳过历史数据,只消费新产生的数据
于是研究了一番,最简单的办法是使用动态不重复的group ID,这样每次启动Kafka client在zookeeper找不到偏移量就会应用auto-offset-reset策略,如果是latest(默认)就会从最新的偏移量开始消费。项目中使用的数据不是那么重要,而数据又是生产者实时发送的,所以希望消费者重启之后,跳过历史数据,只接收并处理生产者新发送的数据。也就是说@KafkaListener参

到底了