
写文章




- @AMiner2006
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
手机上跑MoE?Meta提出MobileMoE,iPhone 16 Pro提速3.8倍
MobileMoE 并为端侧大语言模型建立了新的帕累托前沿,在精度与推理计算开销的权衡上取得了更优结果。

高情商AI Agent来了!剑桥团队推出进化RL框架EvoEmo,靠愤怒、悲伤成功“讨价还价”
EvoEmo:为AI搭起“情感进化流水线”

刚刚,DeepSeek-R1登上Nature封面:朝着AI透明化迈出的可喜一步
开源人工智能(AI)的价值正获得更广泛的认可。刚刚,DeepSeek-R1 论文以封面文章的形式登上了权威科学期刊 Nature,DeepSeek 创始人兼 CEO 梁文峰为该论文的通讯作者。论文链接:https://www.nature.com/articles/s41586-025-09422-z研究团队假设,人类定义的推理模式可能会限制模型的探索,而无限制的强化学习(RL)训练可以更好地激励

韩家炜教授新作:下一代Agentic AI应如何“适配”?
适配(adaptation)已成Agentic AI的研究前沿。

全球首个!Nature重磅研究:计算机视觉告别“偷数据”时代
索尼 AI 推出首个公开可用的、全球多元化的、基于用户同意的数据集。

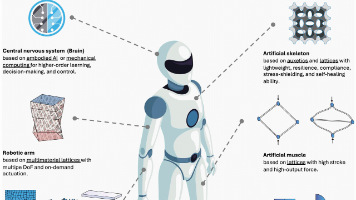
超越大脑智能!Scienc子刊:具身超材料机器人来了
机器人不再是冰冷的躯壳!
全网最详细Agent Harness综述:OpenAI、Anthropic都在押注的,到底是什么?
一篇综述,把Harness工程讲明白了

具身智能新突破:当机器人开始看人类第一视角视频,结果令人意外
统一的 VLA 预训练框架

智谱、清华团队发布GLM-5V-Turbo技术报告:多模态Agent基座模型探索
GLM-5V-Turbo 作为新一代多模态基座模型,在保持纯文本场景下编程、推理、工具调用等能力的前提下,在多模态 Coding、Tool Use、GUI Agent 等方面取得了极具竞争力的性能。

