




- @AGI_Eval
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
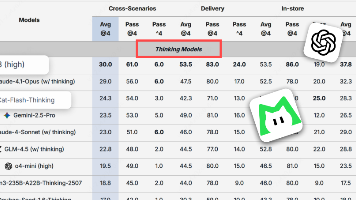
AMO-Bench 的发布及其评测结果,为行业提供了一个观察大模型数学推理能力边界的窗口。从评测数据来看,Gemini 3 Pro 的 63.1% 确立了新的性能基准,而Kimi-K2-Thinking 则展现了国产模型的惊人追赶速度。但值得注意的是,SOTA 模型仍有近 40% 的题目未能稳定解决,这表明复杂数学推理依然是当前 AI 技术亟待攻坚的深水区。

我们提出了一个迭代式的、基于伙伴学习的竞争性评测框架;推出了 CATArena 这一包含多样化、开放式游戏的评测基准;并设计了一套全面的评测矩阵,从而对智能体的核心能力进行可靠、稳定且可扩展的评估。CATArena 的远景不止于此,未来,计划补齐国际象棋与桥牌,在现有四大经典博弈场景的基础上,CATArena 的竞技场将进一步延伸至算法竞赛代码优化、工程代码优化等更为复杂的编程任务中。我们坚信,通
看似是大模型比拼《杀戮尖塔2》游戏能力,实则能直观暴露大模型的真实上限与短板。静态问答中,模型依靠知识与表达就能得分,但爬塔需要局势判断、资源管理、长线规划与试错复盘。这也拉开了模型差距:有的空谈逻辑却难以落地,有的稳步迭代、执行力与纪律性更强。现实里的编程、统筹、长期规划等复杂问题,更像持续闯关的爬塔,而非标准答案式问答。

复旦大学与AGI-Eval社区联合发布《AgentEscapeBench》论文,通过270个密室逃脱游戏测试16个主流AI模型的长程推理能力。研究发现:1)Claude-Opus表现最稳健,25级难度仍保持60%成功率;2)GPT-5.4思路广但效率低,工具调用次数是Claude的2倍;3)模型性能随难度增加呈系统性衰退,工作记忆和逻辑一致性是主要瓶颈。该研究揭示了AI在陌生环境中的真实能力边界,

AI Agent技术体系深度解析:从核心概念到工程实践 本文通过工程师"小A"与初学者"小E"的对话,系统阐述了AI Agent的技术架构与关键组件。主要内容包括: Agent本质是具备自主执行能力的智能体,通过规划、记忆和工具调用三大支柱实现任务闭环 核心技术要素:Token(语义处理单元)、RAG(检索增强生成)、MCP(工具调用协议)、Skill(专业

美团LongCat团队发布VitaBench智能体评测基准,聚焦外卖、餐饮、旅游三大真实生活场景。该基准包含66个工具构成的交互环境,通过深度推理、工具使用和用户交互三个维度量化任务复杂度。实验显示,即使是先进模型在跨场景任务中的成功率仅30%,暴露出与真实应用需求的显著差距。VitaBench采用创新评估方法,如基于Rubric的滑动窗口评估器,为智能体研发提供更精准的评测工具。目前该基准已开源
Rohan Paul 作为一位专注于大型语言模型( LLMs 的研究人工智能领域的专家,也在持续关注其的动态内容,在 DeepSeek 登顶 AppStore 之前,就发布了关于 DeepSeek 的运行指南教程,被查看超过了 78W 次,不得不说, DeepSeek 就是靠这一波又一波的“自来水”霸榜的。最重要的是,在年前 A 股收官的最后一天,直接来了一个开门红,早盘,多支 DeepSeek

复旦大学与AGI-Eval社区联合发布《AgentEscapeBench》论文,通过270个密室逃脱游戏测试16个主流AI模型的长程推理能力。研究发现:1)Claude-Opus表现最稳健,25级难度仍保持60%成功率;2)GPT-5.4思路广但效率低,工具调用次数是Claude的2倍;3)模型性能随难度增加呈系统性衰退,工作记忆和逻辑一致性是主要瓶颈。该研究揭示了AI在陌生环境中的真实能力边界,
最近进入科技社区,大概率会被问到一句话:“你了吗?别误会,这可不是真去搞水产养殖,而是指给AI大模型装上“手脚”——这类智能体框架。它能让 AI 从只会“动嘴”出主意,变成能“动手”操作电脑、写周报、改bug的得力助手,。春节后热度不减,国内大厂和创业公司也纷纷入局,Kimi、腾讯、阿里、字节等都推出了自家的“Claw”产品。今天我们就来盘点一下市面上的“龙虾”到底有啥区别,看看哪只最适合你。

看似是大模型比拼《杀戮尖塔2》游戏能力,实则能直观暴露大模型的真实上限与短板。静态问答中,模型依靠知识与表达就能得分,但爬塔需要局势判断、资源管理、长线规划与试错复盘。这也拉开了模型差距:有的空谈逻辑却难以落地,有的稳步迭代、执行力与纪律性更强。现实里的编程、统筹、长期规划等复杂问题,更像持续闯关的爬塔,而非标准答案式问答。