- @2601_96146209
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
做 PPA 优化时,候选设计必须先通过全部测试,之后再比较面积和延迟的乘积。对功能生成来说,这种策略很合适,因为很多 RTL 错误具有局部可修复性,沿着高分路径深挖,往往能把接近正确的代码推到完全通过。更长的进化搜索又把结构从纯 output-stationary 推向 weight-output stationary hybrid,取消独立权重缓冲,改用直接权重插入和输入广播,延迟进一步降到 7
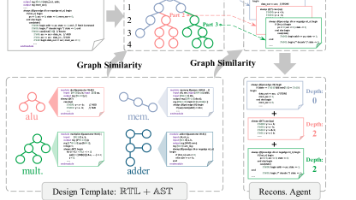
单模块测试包含 add64、mult32、comput、traffic、alu、radix、asyn、accu、fpu_pre、fpu_post、mc_sel、mc_rf、buffer、eth 等设计,平均 217 行、763 个节点、1005 根 wire。功能等价率仍能保持,但 PPA 变差,延迟、面积、功耗比例分别来到 0.89、0.92、0.94,远弱于完整系统的 0.72、0.73、0.
给 Codex 接入 Erie Verilog Generator v0.4.0,让它生成一个带一级缓存的 Ready/Valid 流水寄存器和自检查 Testbench,然后在 macOS 上用 Icarus Verilog 做真实仿真,再用 Yosys 检查综合结构。接口明确、逻辑规模不大的模块,比如协议适配壳、寄存器切片、计数器、简单仲裁和控制状态机,适合走完整生成流程。变化在于,它接到任务
工厂模式与状态机模式的结合,为RTL设计带来了软件工程的严谨性。职责分离:每个模块只做一件事抽象封装:隐藏实现细节,暴露清晰接口可配置架构:通过参数和generate实现灵活扩展我们可以构建出真正可复用、可维护的RTL IP。2026年,随着AI驱动的EDA工具兴起,设计模式的价值将进一步放大。当ChatGPT类工具可以自动生成RTL时,清晰的架构和规范化的模式将成为人机协作的桥梁。毕竟,模糊的意
工厂模式与状态机模式的结合,为RTL设计带来了软件工程的严谨性。职责分离:每个模块只做一件事抽象封装:隐藏实现细节,暴露清晰接口可配置架构:通过参数和generate实现灵活扩展我们可以构建出真正可复用、可维护的RTL IP。2026年,随着AI驱动的EDA工具兴起,设计模式的价值将进一步放大。当ChatGPT类工具可以自动生成RTL时,清晰的架构和规范化的模式将成为人机协作的桥梁。毕竟,模糊的意
工厂模式与状态机模式的结合,为RTL设计带来了软件工程的严谨性。职责分离:每个模块只做一件事抽象封装:隐藏实现细节,暴露清晰接口可配置架构:通过参数和generate实现灵活扩展我们可以构建出真正可复用、可维护的RTL IP。2026年,随着AI驱动的EDA工具兴起,设计模式的价值将进一步放大。当ChatGPT类工具可以自动生成RTL时,清晰的架构和规范化的模式将成为人机协作的桥梁。毕竟,模糊的意
验证覆盖率到92%了,但流片回来还是出问题”——这是许多验证工程师的痛。问题的根源往往不是测试用例不够多,而是验证架构本身缺乏系统性和可复用性。本文将以一个工业级AXI Stream数据通路为例,手把手带你构建一套完整的UVM验证平台。你将学到:如何设计符合UVM规约的Agent架构Sequence与Sequencer的解耦策略Scoreboard的自检机制实现覆盖率收集的最佳实践前置要求:具备S
UCIe 2.0的发布无疑是Chiplet技术发展的重要里程碑。带宽密度翻倍、能效改善、光互连支持、安全扩展——这些升级回应了产业界最迫切的需求。但数据告诉我们,别高兴太早。互连带宽的缺口仍然存在,在最前沿的AI训练场景中,UCIe 2.0的能力可能仍然不足。光互连的承诺诱人,但成本和可靠性问题使其短期内难以大规模部署。先进封装的产能瓶颈正在制约整个产业的发展节奏。侧信道攻击等安全问题提醒我们,C
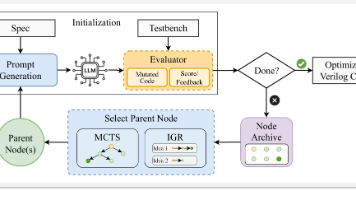
评估完成后,表现最好的策略更新最佳槽位,有潜力但需要继续改进的策略保留在候选池中,新生成但尚未评估的策略标记为待处理。而有了简化提示的引导,系统能够在正确的位置保留关键的中间形式,代价增量从不使用优化时的+55降低到了使用提示时的+15甚至+0,同时运行时间保持在合理的秒级范围。论文中的对比实验也印证了这一判断。在逻辑综合的实验中,论文也观察到一个有趣的现象:当重写空间被Enumo大幅扩展后,原始

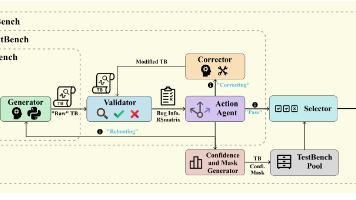
论文实验中,修复迭代上限设为 3,重启上限设为 10。GPT-4o 上,ConfiBench 的 Eval2 为 72.22%,CorrectBench 为 70.13%,提升 2.09 个百分点。GPT-4o-mini 上,ConfiBench 的 Eval2 为 55.56%,CorrectBench 为 47.86%,提升 7.70 个百分点。论文报告的全局验证准确率为 88.85%,并且在