




- @2501_94131507
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
全球经济复杂系统分析框架和《周期破局》系列短视频策划
本文探讨了AI量化投资建模中损失函数的优化问题。针对前期单纯使用软化F1损失函数导致模型仅学习噪声的问题,作者提出了一种融合损失函数方案:将软化F1损失与加权交叉熵损失相结合,并引入类别权重处理数据不平衡。实验发现正负样本权重设置对模型性能影响显著,1:1.2的权重比例效果优于极端悬殊的设置。通过调整样本量和权重比例,模型在6000样本规模下展现出较好的收敛趋势,为后续扩展到更大规模数据集奠定了基
本文分享了AI量化投研中模型训练的意外发现:虽然损失函数表现不佳,但模型在精确度和召回率上取得了突破性结果(最高精确度70.77%)。作者提出三个关键发现:1)当前训练模式具有潜力;2)F1分值已接近目标方向;3)样本权重设置是精细平衡过程。文章重点探讨了两种优化方法:将盈亏比融入损失函数(通过调整正负样本权重),以及直接优化F1分数(采用软化F1计算和加权交叉熵相结合的策略)。最后提出了复合损失
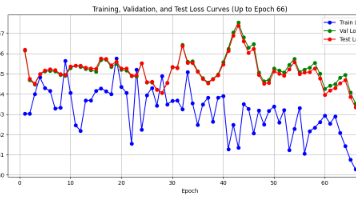
本文记录了AI量化投研建模过程中遇到的问题及优化过程。针对训练失败现象,作者从数据不平衡(正负样本比例92.8%:7.2%)入手,尝试了欠采样、样本加权(正样本权重14.6倍)等方法,但模型仍出现验证集准确率虚高(93.56%)、无法识别正样本的问题。实验显示:1)单纯提高正样本权重会导致模型预测全负;2)调整dropout正则化后,模型仍无法有效学习正样本特征。最终训练曲线呈现发散状态,表明当前
本文总结了基于Swin Transformer模型的AI量化投研建模失败案例。两次训练(5000+和3800+样本)均显示训练损失下降但验证集完全不收敛,模型未能学到有效特征。原因分析包括:1)数据质量问题(特征-标签关联弱/噪声大);2)模型架构不匹配(896×896输入可能过大);3)训练策略问题(学习率/批量大小不当);4)模型过复杂且正则化不足。修正方案着重调整正则化参数(drop_rat
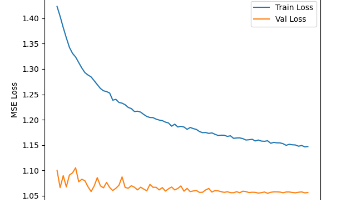
本文介绍了基于Swin Transformer的AI量化投资建模过程。研究团队已完成数据准备(包含多周期K线图和交易结果),选用Swin Transformer网络结构进行建模。数据预处理中发现需对图像和标签进行标准化处理以避免梯度爆炸,但样本数据量已达600GB以上,存储空间面临挑战。在模型训练阶段,采用四合一目标(收益、最大收益、回撤风险、持有期)进行训练,结果显示损失函数下降有限(从1.07